
Note: Already familiar with infrastructure as code (IaC) & terraform? Feel free to jump to best practices section
Terraform & Iac: a 10000 ft overview
If you are working in the SRE/ DevOps space, you must have heard about infrastructure as code (IaC). IaC is an approach to defining & managing infrastructure using code. IaC allows us to follow the same principles that we are familiar and have been using for managing software code and allows us treats the infrastructure as just another software code.
Here are some benefits of IaC:
Check-in infrastructure code in version control systems (VCS).
Easy to review infrastructure changes.
Easy rollbacks to the previous version in case of disaster.
Infrastructure reproducibility increases with a decrease in time to market.
Emphasis on consistency across environments.
Reduction in human errors while provisioning the infrastructure.
Automate provisioning using CI/CD pipelines to promote infrastructure changes across environments.
Overall process becomes more transparent & encourages collaboration.
Now, as we have some idea of IaC, let’s talk about Terraform. It is an open-source tool built by Hashicorp to automate the provisioning of infrastructure resources. It’s the de-facto standard for IaC. It’s a vendor-agnostic tool, and we can manage infrastructure for multiple cloud providers (for example, AWS, Google Cloud, Azure, etc.). To learn more about terraform, please follow this tutorial by Hashicorp.
Let’s dive right into some terraform best practices that have helped us in the past. Later will also be discussing some caveats and workarounds.
Terraform best practices
For ease of demonstration, let’s take the case of an e-commerce company called buytoys.com that sells toys. The company has decided to use terraform to provision their infrastructure and has decided to use AWS as a cloud platform for hosting their services. For getting started, they have also decided to have three different environments Dev, UAT, and Prod. Currently, they have four microservices, and one react app. All these services are under development, and they are planning to go live with one of the onboarding services, which onboard shop owners to the platform.
To run the services, they are planning to use lambda functions. Most of the services will use API Gateway, Database, and Cloudfront Distribution. We will not be discussing the development process & CI/CD for these services as it’s beyond the scope of this blog. We are going to look at it from the infrastructure perspective and will discuss the following topics
Directory structures
Module structures
Where are these modules defined?
Naming conventions
Resource blocks
Manage statefiles
Provider & Terraform Version
So, based on the company’s requirements, here are some crucial findings
There will be three different environments (Dev, UAT, Prod).
Most of the services will use API Gateway, Database, and Cloudfront Distribution.
Directory structure
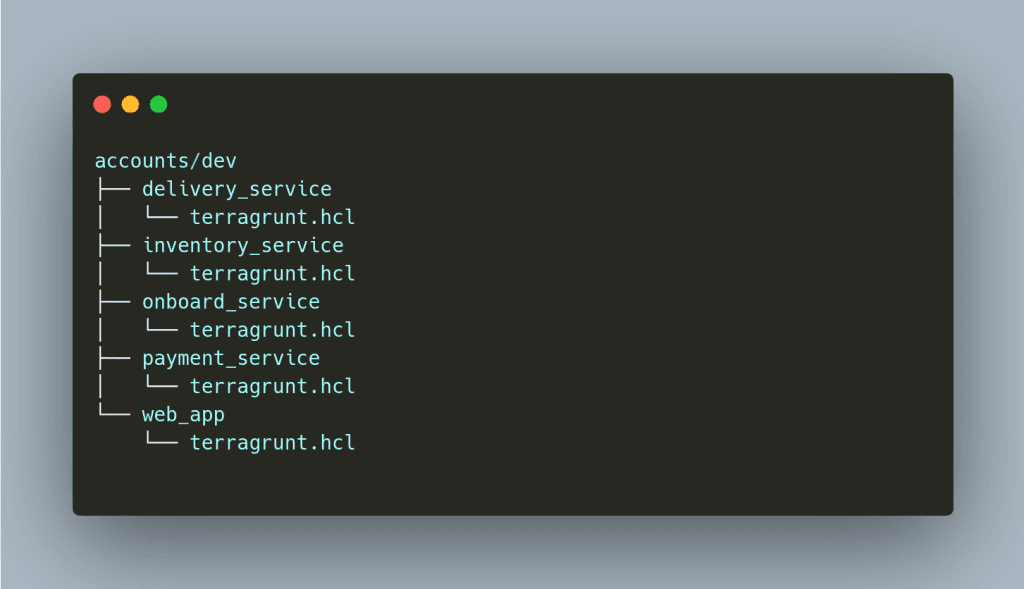
It is best to have separate directories for managing our three environments. Each environment directory will be having the service or app definition as per requirement. Here’s an image showing three different environments inside the accounts directory. Ignore the modules directory for now; we will come back to it later.
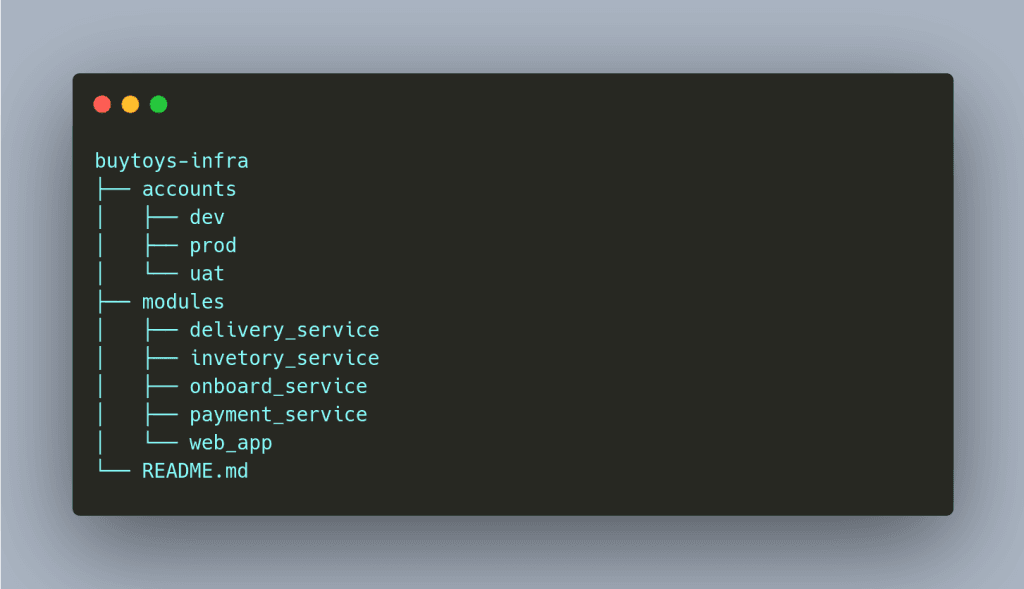
Inside a directory, we have a single configuration file. We will be using terragrunt to keep our code DRY. Also, managing a single file is much easier rather than managing multiple terraform files.
Module structure
Before looking into module structures, let’s spend a minute on what modules are and how we are planning to use them. A module is a collection of resources that can be used without redefining it. If you are from a programming background, think of a function. You define a function that does something; for example, say find the sum of two numbers. And if you want to find the sum of two numbers, you invoke the function with some parameter instead of writing the entire summation logic again.
For core resources such as VPC, DynamoDB, Lambda, etc. We can either use community-written modules. terraform-aws-modules & cloudposse are some of the well known community providers. These are well-tested modules but gives us less control over the module source code.
Another option is writing our modules. We have used this option in the past as it made more sense for us as we wanted more control over the source code and wanted to tweak our modules quickly.
Modules can be defined internally inside the infra repository or externally in a separate GitHub repository. We defined modules in a separate GitHub repository. In the past, we have moved from defining the modules inside the infra directory to a separate GitHub repository, as we wanted to create a versioned release for our modules. Therefore, we pushed the release bundle to S3. This gave us the flexibility to use different versions of the modules and also made them highly available.
We created one API Gateway module with all the terraform resources required for deploying an API Gateway, and we used this module in all our service definitions. In addition, we had defined custom GitHub actions to bundle API Gateway terraform files to the S3 bucket.
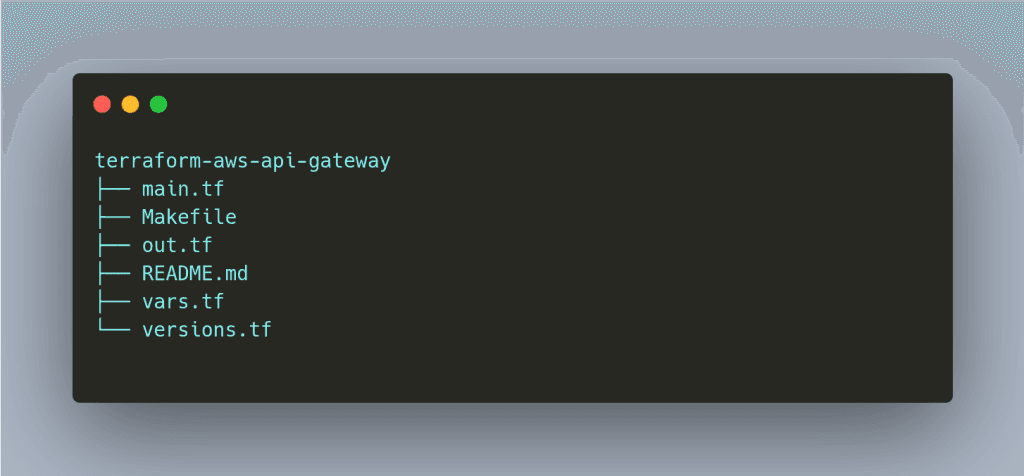
If you are writing your modules, use terraform-docs to generate documentation. This makes life easier while using modules as it mentions the required module parameter and output variables.
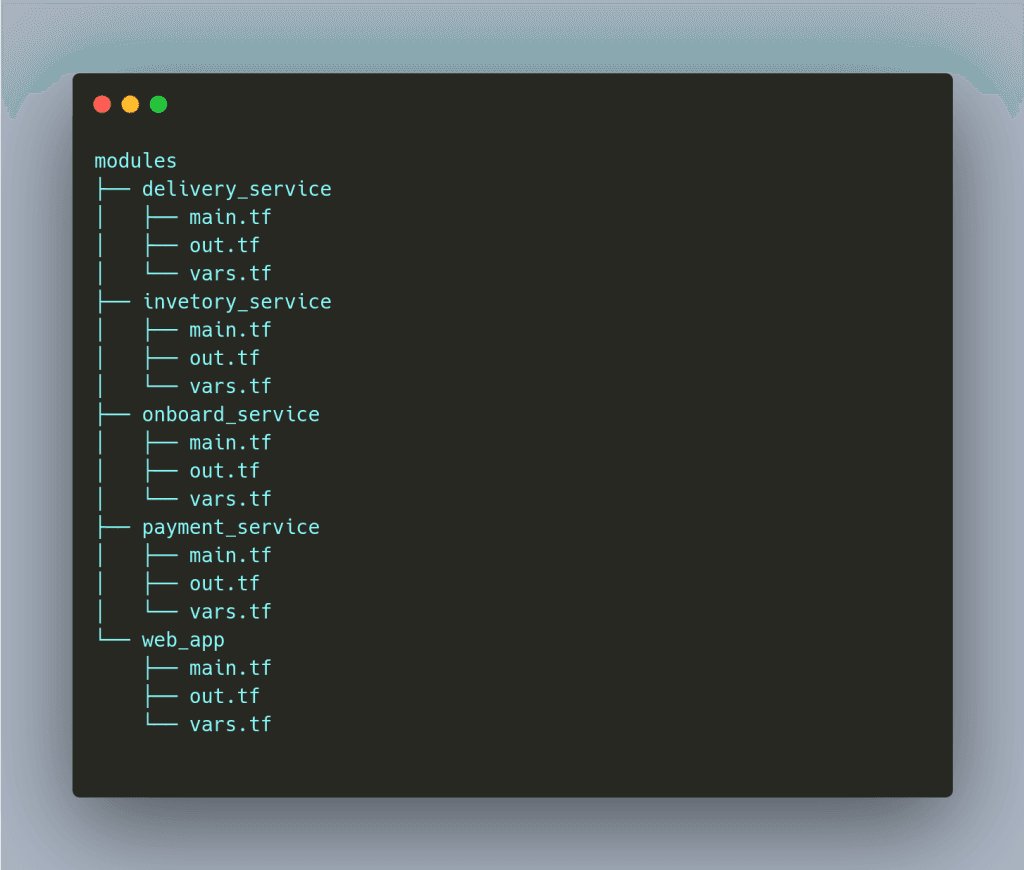
Also, we wanted to define our service/ apps as modules. We defined them internally, which allowed us to keep the code DRY and resources definition consistent across environments. So a service module consisted of all the required resources such as VPC, Lambda, API gateway, etc.
module "api_gateway" { source = "s3::https://s3.amazonaws.com/buytoys-build-artifacts/terraform-modules/terraform-aws-api-gateway/v1.2.3.zip" name = "${local.service_name}-rest-api" env = var.env tags = local.tags api_gateway_types = var.api_gateway_types service_name = local.service_name enable_api_gw_logging = var.enable_api_gw_logging api_gw_logging_level = var.api_gw_logging_level enable_api_gw_access_logging = var.enable_api_gw_access_logging }
Naming conventions
For naming resources visible in the AWS console, we used a general rule of thumb to use hyphens, and for terraform resource names, we used underscore. So, for example, if you want to create an S3 bucket.
resource aws_s3_bucket dummy_s3_bucket { name = "${var.env}-s3-bucket" ... }
Generally, there are two ways to name a terraform file. Either using specific names that tells the purpose of the file. So, for example: If we want to create an S3 resource, we can define all S3 related resources inside a file and name it s3.tf. It helps other developers to get an idea of the contents of the files without actually looking inside it. Another approach is to use something more generic like the main.tf, it’s helpful if we want to use multiple resources or refer to some terraform modules inside the code.
For naming a directory, if the files inside the directory defines a module, then the directory name should be the module name. If the files inside the directory define a service or app, then it should be named as per service or app name.
Internally, terraform merges all .tf into one large file and run the plan accordingly. So it doesn’t matter what name is given to the file. But, having intuitive file names & directory names based on logical grouping helps understand the infrastructure better and makes it easier for the developer to navigate through the code.
Resource blocks
Now, as we understand how to structure and name our files, let’s spend some time discussing some code-level best practices.
Terraform allows us to use count meta argument to create that many resources. So, for example, the following snippet will create four bastions.
count = 4 ami = "ami-a1b2c3d4" instance_type = "t2.micro" tags = { Name = "Server ${count.index}" } }
It’s advisable to keep the count statement on top rather than at the bottom.
2. Use sensitive = true to mark the output-sensitive; Terraform will hide values that are marked sensitive in terraform plan and terraform apply.
output "bastion_private_key_pem" { value = module.bastion.private_key sensitive = true }
3. Adding default values and proper description to variables.
variable "engine_version" { type = string default = "10.14" description = "Engine version for RDS(postgres)" }
4. Adding tags to resources. Tagging resources can be helping in multiple ways. In the past, we have used it to give granular access to developers based on tags.
Manage Statefile
Statefile is a snapshot of the infrastructure and is used as a source of truth by the terraform to plan and apply infrastructure changes. It’s a JSON file consisting of secrets, passwords, and other sensitive information. It should be handled with extra care and should never be pushed to any VCS like Github.
For keeping your state secure, it’s advisable to use some remote store like S3. A backend such as S3 allows us to encrypt our files in transit and at rest, adding confidence that any secrets stored in our statefile are less susceptible to falling into the wrong hands.
Also, it comes with object versioning which is valuable in understanding and debugging what was changed between each terraform apply if a change negatively impacted our service.
Using remote statefiles is very simple; it requires two things.
A S3 bucket that will be used to store the statefile
To Configuring the backend in terraform.
terraform { backend "s3" { bucket = "my-bucket-name" key = "filename.tfstate" region = "eu-west-2" encrypt = true } }
Also its highly discouraged to modify statefile manually until unless you know what you are doing. It is meant to be used by terraform.
Providers & Terraform versions
Terraform uses provider plugins to interact with cloud providers. Pinning terraform, and provider version is helpful for certainty and visibility.
terraform { required_version = ">= 0.13" required_providers { aws = { source = "hashicorp/aws" version = "~> 3.26.0" } } }
Also to manage multiple version of terraform we have used asdf & tfswitch. These tools make switching between versions very easy.
Now, as we have seen, some of the best practices of terraform. Let’s quickly discuss some caveats and possible workarounds.
Caveats
Upgrading to a newer version of terraform or provider with module dependency. To upgrade the provider version or terraform version, we first need to upgrade the version in the modules. So, for example, onboarding-service uses API Gateway, VPC, DB, and Lambda module. So, to upgrade the version of plugins (terraform, AWS) for onboarding service, we first need to upgrade the plugin version in all dependent modules.
Updating security group name & description is terraform destroy and recreate and not update in place. So, this might cause a problem when you want to update the description of the security group attached to a VPC or a DB, and you can’t delete the DB or the VPC. So, terraform will try to delete the security group and create a new one with an updated description. But, the deletion will fail after 15 mins of retrying and by throwing the
DependencyViolationerror. For updating the description of the security group, we found that using a life-cycle meta-argument was helpful.
resource "aws_security_group" "rds_sg" { vpc_id = var.vpc_id description = "AWS Security group for RDS" ... lifecycle { ignore_changes = [ description, ] } }
3. Sometimes, it might happen that if we are updating some resources, it might lead to downtime. So, for example, renaming a DB master username is such one task. This leads to first destroying the older database and recreate a new database with an updated name. This also leads to the loss of data. So we need to come with some custom solution to handle such scenarios.
Conclusion
You can write terraform code in whatever way that suits you. But it should aid developers in fulfilling their primary goal of providing business value.
So to summarize
Logical grouping of resources and files is essential in navigating the code quickly.
If some piece of code is needed multiple times, it’s better to create a module out of it. To keep it DRY.
Each module should do one thing. Either it can create a usable resource or a service, or an app.
Adding descriptions to variables and outputs helps while calling that module.
If you are working in a large team, setting up a remote backend for terraform is essential to prevent stepping on someone else’s toe.
Modifying statefile manually is like playing with fire. Please do whatever you can to avoid it.
It’s essential to have a code of conduct documented if the team size is large, as it acts as a reference document for the members to follow these unsaid guidelines.
Note: Already familiar with infrastructure as code (IaC) & terraform? Feel free to jump to best practices section
Terraform & Iac: a 10000 ft overview
If you are working in the SRE/ DevOps space, you must have heard about infrastructure as code (IaC). IaC is an approach to defining & managing infrastructure using code. IaC allows us to follow the same principles that we are familiar and have been using for managing software code and allows us treats the infrastructure as just another software code.
Here are some benefits of IaC:
Check-in infrastructure code in version control systems (VCS).
Easy to review infrastructure changes.
Easy rollbacks to the previous version in case of disaster.
Infrastructure reproducibility increases with a decrease in time to market.
Emphasis on consistency across environments.
Reduction in human errors while provisioning the infrastructure.
Automate provisioning using CI/CD pipelines to promote infrastructure changes across environments.
Overall process becomes more transparent & encourages collaboration.
Now, as we have some idea of IaC, let’s talk about Terraform. It is an open-source tool built by Hashicorp to automate the provisioning of infrastructure resources. It’s the de-facto standard for IaC. It’s a vendor-agnostic tool, and we can manage infrastructure for multiple cloud providers (for example, AWS, Google Cloud, Azure, etc.). To learn more about terraform, please follow this tutorial by Hashicorp.
Let’s dive right into some terraform best practices that have helped us in the past. Later will also be discussing some caveats and workarounds.
Terraform best practices
For ease of demonstration, let’s take the case of an e-commerce company called buytoys.com that sells toys. The company has decided to use terraform to provision their infrastructure and has decided to use AWS as a cloud platform for hosting their services. For getting started, they have also decided to have three different environments Dev, UAT, and Prod. Currently, they have four microservices, and one react app. All these services are under development, and they are planning to go live with one of the onboarding services, which onboard shop owners to the platform.
To run the services, they are planning to use lambda functions. Most of the services will use API Gateway, Database, and Cloudfront Distribution. We will not be discussing the development process & CI/CD for these services as it’s beyond the scope of this blog. We are going to look at it from the infrastructure perspective and will discuss the following topics
Directory structures
Module structures
Where are these modules defined?
Naming conventions
Resource blocks
Manage statefiles
Provider & Terraform Version
So, based on the company’s requirements, here are some crucial findings
There will be three different environments (Dev, UAT, Prod).
Most of the services will use API Gateway, Database, and Cloudfront Distribution.
Directory structure
It is best to have separate directories for managing our three environments. Each environment directory will be having the service or app definition as per requirement. Here’s an image showing three different environments inside the accounts directory. Ignore the modules directory for now; we will come back to it later.
Inside a directory, we have a single configuration file. We will be using terragrunt to keep our code DRY. Also, managing a single file is much easier rather than managing multiple terraform files.
Module structure
Before looking into module structures, let’s spend a minute on what modules are and how we are planning to use them. A module is a collection of resources that can be used without redefining it. If you are from a programming background, think of a function. You define a function that does something; for example, say find the sum of two numbers. And if you want to find the sum of two numbers, you invoke the function with some parameter instead of writing the entire summation logic again.
For core resources such as VPC, DynamoDB, Lambda, etc. We can either use community-written modules. terraform-aws-modules & cloudposse are some of the well known community providers. These are well-tested modules but gives us less control over the module source code.
Another option is writing our modules. We have used this option in the past as it made more sense for us as we wanted more control over the source code and wanted to tweak our modules quickly.
Modules can be defined internally inside the infra repository or externally in a separate GitHub repository. We defined modules in a separate GitHub repository. In the past, we have moved from defining the modules inside the infra directory to a separate GitHub repository, as we wanted to create a versioned release for our modules. Therefore, we pushed the release bundle to S3. This gave us the flexibility to use different versions of the modules and also made them highly available.
We created one API Gateway module with all the terraform resources required for deploying an API Gateway, and we used this module in all our service definitions. In addition, we had defined custom GitHub actions to bundle API Gateway terraform files to the S3 bucket.
If you are writing your modules, use terraform-docs to generate documentation. This makes life easier while using modules as it mentions the required module parameter and output variables.
Also, we wanted to define our service/ apps as modules. We defined them internally, which allowed us to keep the code DRY and resources definition consistent across environments. So a service module consisted of all the required resources such as VPC, Lambda, API gateway, etc.
module "api_gateway" { source = "s3::https://s3.amazonaws.com/buytoys-build-artifacts/terraform-modules/terraform-aws-api-gateway/v1.2.3.zip" name = "${local.service_name}-rest-api" env = var.env tags = local.tags api_gateway_types = var.api_gateway_types service_name = local.service_name enable_api_gw_logging = var.enable_api_gw_logging api_gw_logging_level = var.api_gw_logging_level enable_api_gw_access_logging = var.enable_api_gw_access_logging }
Naming conventions
For naming resources visible in the AWS console, we used a general rule of thumb to use hyphens, and for terraform resource names, we used underscore. So, for example, if you want to create an S3 bucket.
resource aws_s3_bucket dummy_s3_bucket { name = "${var.env}-s3-bucket" ... }
Generally, there are two ways to name a terraform file. Either using specific names that tells the purpose of the file. So, for example: If we want to create an S3 resource, we can define all S3 related resources inside a file and name it s3.tf. It helps other developers to get an idea of the contents of the files without actually looking inside it. Another approach is to use something more generic like the main.tf, it’s helpful if we want to use multiple resources or refer to some terraform modules inside the code.
For naming a directory, if the files inside the directory defines a module, then the directory name should be the module name. If the files inside the directory define a service or app, then it should be named as per service or app name.
Internally, terraform merges all .tf into one large file and run the plan accordingly. So it doesn’t matter what name is given to the file. But, having intuitive file names & directory names based on logical grouping helps understand the infrastructure better and makes it easier for the developer to navigate through the code.
Resource blocks
Now, as we understand how to structure and name our files, let’s spend some time discussing some code-level best practices.
Terraform allows us to use count meta argument to create that many resources. So, for example, the following snippet will create four bastions.
count = 4 ami = "ami-a1b2c3d4" instance_type = "t2.micro" tags = { Name = "Server ${count.index}" } }
It’s advisable to keep the count statement on top rather than at the bottom.
2. Use sensitive = true to mark the output-sensitive; Terraform will hide values that are marked sensitive in terraform plan and terraform apply.
output "bastion_private_key_pem" { value = module.bastion.private_key sensitive = true }
3. Adding default values and proper description to variables.
variable "engine_version" { type = string default = "10.14" description = "Engine version for RDS(postgres)" }
4. Adding tags to resources. Tagging resources can be helping in multiple ways. In the past, we have used it to give granular access to developers based on tags.
Manage Statefile
Statefile is a snapshot of the infrastructure and is used as a source of truth by the terraform to plan and apply infrastructure changes. It’s a JSON file consisting of secrets, passwords, and other sensitive information. It should be handled with extra care and should never be pushed to any VCS like Github.
For keeping your state secure, it’s advisable to use some remote store like S3. A backend such as S3 allows us to encrypt our files in transit and at rest, adding confidence that any secrets stored in our statefile are less susceptible to falling into the wrong hands.
Also, it comes with object versioning which is valuable in understanding and debugging what was changed between each terraform apply if a change negatively impacted our service.
Using remote statefiles is very simple; it requires two things.
A S3 bucket that will be used to store the statefile
To Configuring the backend in terraform.
terraform { backend "s3" { bucket = "my-bucket-name" key = "filename.tfstate" region = "eu-west-2" encrypt = true } }
Also its highly discouraged to modify statefile manually until unless you know what you are doing. It is meant to be used by terraform.
Providers & Terraform versions
Terraform uses provider plugins to interact with cloud providers. Pinning terraform, and provider version is helpful for certainty and visibility.
terraform { required_version = ">= 0.13" required_providers { aws = { source = "hashicorp/aws" version = "~> 3.26.0" } } }
Also to manage multiple version of terraform we have used asdf & tfswitch. These tools make switching between versions very easy.
Now, as we have seen, some of the best practices of terraform. Let’s quickly discuss some caveats and possible workarounds.
Caveats
Upgrading to a newer version of terraform or provider with module dependency. To upgrade the provider version or terraform version, we first need to upgrade the version in the modules. So, for example, onboarding-service uses API Gateway, VPC, DB, and Lambda module. So, to upgrade the version of plugins (terraform, AWS) for onboarding service, we first need to upgrade the plugin version in all dependent modules.
Updating security group name & description is terraform destroy and recreate and not update in place. So, this might cause a problem when you want to update the description of the security group attached to a VPC or a DB, and you can’t delete the DB or the VPC. So, terraform will try to delete the security group and create a new one with an updated description. But, the deletion will fail after 15 mins of retrying and by throwing the
DependencyViolationerror. For updating the description of the security group, we found that using a life-cycle meta-argument was helpful.
resource "aws_security_group" "rds_sg" { vpc_id = var.vpc_id description = "AWS Security group for RDS" ... lifecycle { ignore_changes = [ description, ] } }
3. Sometimes, it might happen that if we are updating some resources, it might lead to downtime. So, for example, renaming a DB master username is such one task. This leads to first destroying the older database and recreate a new database with an updated name. This also leads to the loss of data. So we need to come with some custom solution to handle such scenarios.
Conclusion
You can write terraform code in whatever way that suits you. But it should aid developers in fulfilling their primary goal of providing business value.
So to summarize
Logical grouping of resources and files is essential in navigating the code quickly.
If some piece of code is needed multiple times, it’s better to create a module out of it. To keep it DRY.
Each module should do one thing. Either it can create a usable resource or a service, or an app.
Adding descriptions to variables and outputs helps while calling that module.
If you are working in a large team, setting up a remote backend for terraform is essential to prevent stepping on someone else’s toe.
Modifying statefile manually is like playing with fire. Please do whatever you can to avoid it.
It’s essential to have a code of conduct documented if the team size is large, as it acts as a reference document for the members to follow these unsaid guidelines.
Note: Already familiar with infrastructure as code (IaC) & terraform? Feel free to jump to best practices section
Terraform & Iac: a 10000 ft overview
If you are working in the SRE/ DevOps space, you must have heard about infrastructure as code (IaC). IaC is an approach to defining & managing infrastructure using code. IaC allows us to follow the same principles that we are familiar and have been using for managing software code and allows us treats the infrastructure as just another software code.
Here are some benefits of IaC:
Check-in infrastructure code in version control systems (VCS).
Easy to review infrastructure changes.
Easy rollbacks to the previous version in case of disaster.
Infrastructure reproducibility increases with a decrease in time to market.
Emphasis on consistency across environments.
Reduction in human errors while provisioning the infrastructure.
Automate provisioning using CI/CD pipelines to promote infrastructure changes across environments.
Overall process becomes more transparent & encourages collaboration.
Now, as we have some idea of IaC, let’s talk about Terraform. It is an open-source tool built by Hashicorp to automate the provisioning of infrastructure resources. It’s the de-facto standard for IaC. It’s a vendor-agnostic tool, and we can manage infrastructure for multiple cloud providers (for example, AWS, Google Cloud, Azure, etc.). To learn more about terraform, please follow this tutorial by Hashicorp.
Let’s dive right into some terraform best practices that have helped us in the past. Later will also be discussing some caveats and workarounds.
Terraform best practices
For ease of demonstration, let’s take the case of an e-commerce company called buytoys.com that sells toys. The company has decided to use terraform to provision their infrastructure and has decided to use AWS as a cloud platform for hosting their services. For getting started, they have also decided to have three different environments Dev, UAT, and Prod. Currently, they have four microservices, and one react app. All these services are under development, and they are planning to go live with one of the onboarding services, which onboard shop owners to the platform.
To run the services, they are planning to use lambda functions. Most of the services will use API Gateway, Database, and Cloudfront Distribution. We will not be discussing the development process & CI/CD for these services as it’s beyond the scope of this blog. We are going to look at it from the infrastructure perspective and will discuss the following topics
Directory structures
Module structures
Where are these modules defined?
Naming conventions
Resource blocks
Manage statefiles
Provider & Terraform Version
So, based on the company’s requirements, here are some crucial findings
There will be three different environments (Dev, UAT, Prod).
Most of the services will use API Gateway, Database, and Cloudfront Distribution.
Directory structure
It is best to have separate directories for managing our three environments. Each environment directory will be having the service or app definition as per requirement. Here’s an image showing three different environments inside the accounts directory. Ignore the modules directory for now; we will come back to it later.
Inside a directory, we have a single configuration file. We will be using terragrunt to keep our code DRY. Also, managing a single file is much easier rather than managing multiple terraform files.
Module structure
Before looking into module structures, let’s spend a minute on what modules are and how we are planning to use them. A module is a collection of resources that can be used without redefining it. If you are from a programming background, think of a function. You define a function that does something; for example, say find the sum of two numbers. And if you want to find the sum of two numbers, you invoke the function with some parameter instead of writing the entire summation logic again.
For core resources such as VPC, DynamoDB, Lambda, etc. We can either use community-written modules. terraform-aws-modules & cloudposse are some of the well known community providers. These are well-tested modules but gives us less control over the module source code.
Another option is writing our modules. We have used this option in the past as it made more sense for us as we wanted more control over the source code and wanted to tweak our modules quickly.
Modules can be defined internally inside the infra repository or externally in a separate GitHub repository. We defined modules in a separate GitHub repository. In the past, we have moved from defining the modules inside the infra directory to a separate GitHub repository, as we wanted to create a versioned release for our modules. Therefore, we pushed the release bundle to S3. This gave us the flexibility to use different versions of the modules and also made them highly available.
We created one API Gateway module with all the terraform resources required for deploying an API Gateway, and we used this module in all our service definitions. In addition, we had defined custom GitHub actions to bundle API Gateway terraform files to the S3 bucket.
If you are writing your modules, use terraform-docs to generate documentation. This makes life easier while using modules as it mentions the required module parameter and output variables.
Also, we wanted to define our service/ apps as modules. We defined them internally, which allowed us to keep the code DRY and resources definition consistent across environments. So a service module consisted of all the required resources such as VPC, Lambda, API gateway, etc.
module "api_gateway" { source = "s3::https://s3.amazonaws.com/buytoys-build-artifacts/terraform-modules/terraform-aws-api-gateway/v1.2.3.zip" name = "${local.service_name}-rest-api" env = var.env tags = local.tags api_gateway_types = var.api_gateway_types service_name = local.service_name enable_api_gw_logging = var.enable_api_gw_logging api_gw_logging_level = var.api_gw_logging_level enable_api_gw_access_logging = var.enable_api_gw_access_logging }
Naming conventions
For naming resources visible in the AWS console, we used a general rule of thumb to use hyphens, and for terraform resource names, we used underscore. So, for example, if you want to create an S3 bucket.
resource aws_s3_bucket dummy_s3_bucket { name = "${var.env}-s3-bucket" ... }
Generally, there are two ways to name a terraform file. Either using specific names that tells the purpose of the file. So, for example: If we want to create an S3 resource, we can define all S3 related resources inside a file and name it s3.tf. It helps other developers to get an idea of the contents of the files without actually looking inside it. Another approach is to use something more generic like the main.tf, it’s helpful if we want to use multiple resources or refer to some terraform modules inside the code.
For naming a directory, if the files inside the directory defines a module, then the directory name should be the module name. If the files inside the directory define a service or app, then it should be named as per service or app name.
Internally, terraform merges all .tf into one large file and run the plan accordingly. So it doesn’t matter what name is given to the file. But, having intuitive file names & directory names based on logical grouping helps understand the infrastructure better and makes it easier for the developer to navigate through the code.
Resource blocks
Now, as we understand how to structure and name our files, let’s spend some time discussing some code-level best practices.
Terraform allows us to use count meta argument to create that many resources. So, for example, the following snippet will create four bastions.
count = 4 ami = "ami-a1b2c3d4" instance_type = "t2.micro" tags = { Name = "Server ${count.index}" } }
It’s advisable to keep the count statement on top rather than at the bottom.
2. Use sensitive = true to mark the output-sensitive; Terraform will hide values that are marked sensitive in terraform plan and terraform apply.
output "bastion_private_key_pem" { value = module.bastion.private_key sensitive = true }
3. Adding default values and proper description to variables.
variable "engine_version" { type = string default = "10.14" description = "Engine version for RDS(postgres)" }
4. Adding tags to resources. Tagging resources can be helping in multiple ways. In the past, we have used it to give granular access to developers based on tags.
Manage Statefile
Statefile is a snapshot of the infrastructure and is used as a source of truth by the terraform to plan and apply infrastructure changes. It’s a JSON file consisting of secrets, passwords, and other sensitive information. It should be handled with extra care and should never be pushed to any VCS like Github.
For keeping your state secure, it’s advisable to use some remote store like S3. A backend such as S3 allows us to encrypt our files in transit and at rest, adding confidence that any secrets stored in our statefile are less susceptible to falling into the wrong hands.
Also, it comes with object versioning which is valuable in understanding and debugging what was changed between each terraform apply if a change negatively impacted our service.
Using remote statefiles is very simple; it requires two things.
A S3 bucket that will be used to store the statefile
To Configuring the backend in terraform.
terraform { backend "s3" { bucket = "my-bucket-name" key = "filename.tfstate" region = "eu-west-2" encrypt = true } }
Also its highly discouraged to modify statefile manually until unless you know what you are doing. It is meant to be used by terraform.
Providers & Terraform versions
Terraform uses provider plugins to interact with cloud providers. Pinning terraform, and provider version is helpful for certainty and visibility.
terraform { required_version = ">= 0.13" required_providers { aws = { source = "hashicorp/aws" version = "~> 3.26.0" } } }
Also to manage multiple version of terraform we have used asdf & tfswitch. These tools make switching between versions very easy.
Now, as we have seen, some of the best practices of terraform. Let’s quickly discuss some caveats and possible workarounds.
Caveats
Upgrading to a newer version of terraform or provider with module dependency. To upgrade the provider version or terraform version, we first need to upgrade the version in the modules. So, for example, onboarding-service uses API Gateway, VPC, DB, and Lambda module. So, to upgrade the version of plugins (terraform, AWS) for onboarding service, we first need to upgrade the plugin version in all dependent modules.
Updating security group name & description is terraform destroy and recreate and not update in place. So, this might cause a problem when you want to update the description of the security group attached to a VPC or a DB, and you can’t delete the DB or the VPC. So, terraform will try to delete the security group and create a new one with an updated description. But, the deletion will fail after 15 mins of retrying and by throwing the
DependencyViolationerror. For updating the description of the security group, we found that using a life-cycle meta-argument was helpful.
resource "aws_security_group" "rds_sg" { vpc_id = var.vpc_id description = "AWS Security group for RDS" ... lifecycle { ignore_changes = [ description, ] } }
3. Sometimes, it might happen that if we are updating some resources, it might lead to downtime. So, for example, renaming a DB master username is such one task. This leads to first destroying the older database and recreate a new database with an updated name. This also leads to the loss of data. So we need to come with some custom solution to handle such scenarios.
Conclusion
You can write terraform code in whatever way that suits you. But it should aid developers in fulfilling their primary goal of providing business value.
So to summarize
Logical grouping of resources and files is essential in navigating the code quickly.
If some piece of code is needed multiple times, it’s better to create a module out of it. To keep it DRY.
Each module should do one thing. Either it can create a usable resource or a service, or an app.
Adding descriptions to variables and outputs helps while calling that module.
If you are working in a large team, setting up a remote backend for terraform is essential to prevent stepping on someone else’s toe.
Modifying statefile manually is like playing with fire. Please do whatever you can to avoid it.
It’s essential to have a code of conduct documented if the team size is large, as it acts as a reference document for the members to follow these unsaid guidelines.
Note: Already familiar with infrastructure as code (IaC) & terraform? Feel free to jump to best practices section
Terraform & Iac: a 10000 ft overview
If you are working in the SRE/ DevOps space, you must have heard about infrastructure as code (IaC). IaC is an approach to defining & managing infrastructure using code. IaC allows us to follow the same principles that we are familiar and have been using for managing software code and allows us treats the infrastructure as just another software code.
Here are some benefits of IaC:
Check-in infrastructure code in version control systems (VCS).
Easy to review infrastructure changes.
Easy rollbacks to the previous version in case of disaster.
Infrastructure reproducibility increases with a decrease in time to market.
Emphasis on consistency across environments.
Reduction in human errors while provisioning the infrastructure.
Automate provisioning using CI/CD pipelines to promote infrastructure changes across environments.
Overall process becomes more transparent & encourages collaboration.
Now, as we have some idea of IaC, let’s talk about Terraform. It is an open-source tool built by Hashicorp to automate the provisioning of infrastructure resources. It’s the de-facto standard for IaC. It’s a vendor-agnostic tool, and we can manage infrastructure for multiple cloud providers (for example, AWS, Google Cloud, Azure, etc.). To learn more about terraform, please follow this tutorial by Hashicorp.
Let’s dive right into some terraform best practices that have helped us in the past. Later will also be discussing some caveats and workarounds.
Terraform best practices
For ease of demonstration, let’s take the case of an e-commerce company called buytoys.com that sells toys. The company has decided to use terraform to provision their infrastructure and has decided to use AWS as a cloud platform for hosting their services. For getting started, they have also decided to have three different environments Dev, UAT, and Prod. Currently, they have four microservices, and one react app. All these services are under development, and they are planning to go live with one of the onboarding services, which onboard shop owners to the platform.
To run the services, they are planning to use lambda functions. Most of the services will use API Gateway, Database, and Cloudfront Distribution. We will not be discussing the development process & CI/CD for these services as it’s beyond the scope of this blog. We are going to look at it from the infrastructure perspective and will discuss the following topics
Directory structures
Module structures
Where are these modules defined?
Naming conventions
Resource blocks
Manage statefiles
Provider & Terraform Version
So, based on the company’s requirements, here are some crucial findings
There will be three different environments (Dev, UAT, Prod).
Most of the services will use API Gateway, Database, and Cloudfront Distribution.
Directory structure
It is best to have separate directories for managing our three environments. Each environment directory will be having the service or app definition as per requirement. Here’s an image showing three different environments inside the accounts directory. Ignore the modules directory for now; we will come back to it later.
Inside a directory, we have a single configuration file. We will be using terragrunt to keep our code DRY. Also, managing a single file is much easier rather than managing multiple terraform files.
Module structure
Before looking into module structures, let’s spend a minute on what modules are and how we are planning to use them. A module is a collection of resources that can be used without redefining it. If you are from a programming background, think of a function. You define a function that does something; for example, say find the sum of two numbers. And if you want to find the sum of two numbers, you invoke the function with some parameter instead of writing the entire summation logic again.
For core resources such as VPC, DynamoDB, Lambda, etc. We can either use community-written modules. terraform-aws-modules & cloudposse are some of the well known community providers. These are well-tested modules but gives us less control over the module source code.
Another option is writing our modules. We have used this option in the past as it made more sense for us as we wanted more control over the source code and wanted to tweak our modules quickly.
Modules can be defined internally inside the infra repository or externally in a separate GitHub repository. We defined modules in a separate GitHub repository. In the past, we have moved from defining the modules inside the infra directory to a separate GitHub repository, as we wanted to create a versioned release for our modules. Therefore, we pushed the release bundle to S3. This gave us the flexibility to use different versions of the modules and also made them highly available.
We created one API Gateway module with all the terraform resources required for deploying an API Gateway, and we used this module in all our service definitions. In addition, we had defined custom GitHub actions to bundle API Gateway terraform files to the S3 bucket.
If you are writing your modules, use terraform-docs to generate documentation. This makes life easier while using modules as it mentions the required module parameter and output variables.
Also, we wanted to define our service/ apps as modules. We defined them internally, which allowed us to keep the code DRY and resources definition consistent across environments. So a service module consisted of all the required resources such as VPC, Lambda, API gateway, etc.
module "api_gateway" { source = "s3::https://s3.amazonaws.com/buytoys-build-artifacts/terraform-modules/terraform-aws-api-gateway/v1.2.3.zip" name = "${local.service_name}-rest-api" env = var.env tags = local.tags api_gateway_types = var.api_gateway_types service_name = local.service_name enable_api_gw_logging = var.enable_api_gw_logging api_gw_logging_level = var.api_gw_logging_level enable_api_gw_access_logging = var.enable_api_gw_access_logging }
Naming conventions
For naming resources visible in the AWS console, we used a general rule of thumb to use hyphens, and for terraform resource names, we used underscore. So, for example, if you want to create an S3 bucket.
resource aws_s3_bucket dummy_s3_bucket { name = "${var.env}-s3-bucket" ... }
Generally, there are two ways to name a terraform file. Either using specific names that tells the purpose of the file. So, for example: If we want to create an S3 resource, we can define all S3 related resources inside a file and name it s3.tf. It helps other developers to get an idea of the contents of the files without actually looking inside it. Another approach is to use something more generic like the main.tf, it’s helpful if we want to use multiple resources or refer to some terraform modules inside the code.
For naming a directory, if the files inside the directory defines a module, then the directory name should be the module name. If the files inside the directory define a service or app, then it should be named as per service or app name.
Internally, terraform merges all .tf into one large file and run the plan accordingly. So it doesn’t matter what name is given to the file. But, having intuitive file names & directory names based on logical grouping helps understand the infrastructure better and makes it easier for the developer to navigate through the code.
Resource blocks
Now, as we understand how to structure and name our files, let’s spend some time discussing some code-level best practices.
Terraform allows us to use count meta argument to create that many resources. So, for example, the following snippet will create four bastions.
count = 4 ami = "ami-a1b2c3d4" instance_type = "t2.micro" tags = { Name = "Server ${count.index}" } }
It’s advisable to keep the count statement on top rather than at the bottom.
2. Use sensitive = true to mark the output-sensitive; Terraform will hide values that are marked sensitive in terraform plan and terraform apply.
output "bastion_private_key_pem" { value = module.bastion.private_key sensitive = true }
3. Adding default values and proper description to variables.
variable "engine_version" { type = string default = "10.14" description = "Engine version for RDS(postgres)" }
4. Adding tags to resources. Tagging resources can be helping in multiple ways. In the past, we have used it to give granular access to developers based on tags.
Manage Statefile
Statefile is a snapshot of the infrastructure and is used as a source of truth by the terraform to plan and apply infrastructure changes. It’s a JSON file consisting of secrets, passwords, and other sensitive information. It should be handled with extra care and should never be pushed to any VCS like Github.
For keeping your state secure, it’s advisable to use some remote store like S3. A backend such as S3 allows us to encrypt our files in transit and at rest, adding confidence that any secrets stored in our statefile are less susceptible to falling into the wrong hands.
Also, it comes with object versioning which is valuable in understanding and debugging what was changed between each terraform apply if a change negatively impacted our service.
Using remote statefiles is very simple; it requires two things.
A S3 bucket that will be used to store the statefile
To Configuring the backend in terraform.
terraform { backend "s3" { bucket = "my-bucket-name" key = "filename.tfstate" region = "eu-west-2" encrypt = true } }
Also its highly discouraged to modify statefile manually until unless you know what you are doing. It is meant to be used by terraform.
Providers & Terraform versions
Terraform uses provider plugins to interact with cloud providers. Pinning terraform, and provider version is helpful for certainty and visibility.
terraform { required_version = ">= 0.13" required_providers { aws = { source = "hashicorp/aws" version = "~> 3.26.0" } } }
Also to manage multiple version of terraform we have used asdf & tfswitch. These tools make switching between versions very easy.
Now, as we have seen, some of the best practices of terraform. Let’s quickly discuss some caveats and possible workarounds.
Caveats
Upgrading to a newer version of terraform or provider with module dependency. To upgrade the provider version or terraform version, we first need to upgrade the version in the modules. So, for example, onboarding-service uses API Gateway, VPC, DB, and Lambda module. So, to upgrade the version of plugins (terraform, AWS) for onboarding service, we first need to upgrade the plugin version in all dependent modules.
Updating security group name & description is terraform destroy and recreate and not update in place. So, this might cause a problem when you want to update the description of the security group attached to a VPC or a DB, and you can’t delete the DB or the VPC. So, terraform will try to delete the security group and create a new one with an updated description. But, the deletion will fail after 15 mins of retrying and by throwing the
DependencyViolationerror. For updating the description of the security group, we found that using a life-cycle meta-argument was helpful.
resource "aws_security_group" "rds_sg" { vpc_id = var.vpc_id description = "AWS Security group for RDS" ... lifecycle { ignore_changes = [ description, ] } }
3. Sometimes, it might happen that if we are updating some resources, it might lead to downtime. So, for example, renaming a DB master username is such one task. This leads to first destroying the older database and recreate a new database with an updated name. This also leads to the loss of data. So we need to come with some custom solution to handle such scenarios.
Conclusion
You can write terraform code in whatever way that suits you. But it should aid developers in fulfilling their primary goal of providing business value.
So to summarize
Logical grouping of resources and files is essential in navigating the code quickly.
If some piece of code is needed multiple times, it’s better to create a module out of it. To keep it DRY.
Each module should do one thing. Either it can create a usable resource or a service, or an app.
Adding descriptions to variables and outputs helps while calling that module.
If you are working in a large team, setting up a remote backend for terraform is essential to prevent stepping on someone else’s toe.
Modifying statefile manually is like playing with fire. Please do whatever you can to avoid it.
It’s essential to have a code of conduct documented if the team size is large, as it acts as a reference document for the members to follow these unsaid guidelines.
Note: Already familiar with infrastructure as code (IaC) & terraform? Feel free to jump to best practices section
Terraform & Iac: a 10000 ft overview
If you are working in the SRE/ DevOps space, you must have heard about infrastructure as code (IaC). IaC is an approach to defining & managing infrastructure using code. IaC allows us to follow the same principles that we are familiar and have been using for managing software code and allows us treats the infrastructure as just another software code.
Here are some benefits of IaC:
Check-in infrastructure code in version control systems (VCS).
Easy to review infrastructure changes.
Easy rollbacks to the previous version in case of disaster.
Infrastructure reproducibility increases with a decrease in time to market.
Emphasis on consistency across environments.
Reduction in human errors while provisioning the infrastructure.
Automate provisioning using CI/CD pipelines to promote infrastructure changes across environments.
Overall process becomes more transparent & encourages collaboration.
Now, as we have some idea of IaC, let’s talk about Terraform. It is an open-source tool built by Hashicorp to automate the provisioning of infrastructure resources. It’s the de-facto standard for IaC. It’s a vendor-agnostic tool, and we can manage infrastructure for multiple cloud providers (for example, AWS, Google Cloud, Azure, etc.). To learn more about terraform, please follow this tutorial by Hashicorp.
Let’s dive right into some terraform best practices that have helped us in the past. Later will also be discussing some caveats and workarounds.
Terraform best practices
For ease of demonstration, let’s take the case of an e-commerce company called buytoys.com that sells toys. The company has decided to use terraform to provision their infrastructure and has decided to use AWS as a cloud platform for hosting their services. For getting started, they have also decided to have three different environments Dev, UAT, and Prod. Currently, they have four microservices, and one react app. All these services are under development, and they are planning to go live with one of the onboarding services, which onboard shop owners to the platform.
To run the services, they are planning to use lambda functions. Most of the services will use API Gateway, Database, and Cloudfront Distribution. We will not be discussing the development process & CI/CD for these services as it’s beyond the scope of this blog. We are going to look at it from the infrastructure perspective and will discuss the following topics
Directory structures
Module structures
Where are these modules defined?
Naming conventions
Resource blocks
Manage statefiles
Provider & Terraform Version
So, based on the company’s requirements, here are some crucial findings
There will be three different environments (Dev, UAT, Prod).
Most of the services will use API Gateway, Database, and Cloudfront Distribution.
Directory structure
It is best to have separate directories for managing our three environments. Each environment directory will be having the service or app definition as per requirement. Here’s an image showing three different environments inside the accounts directory. Ignore the modules directory for now; we will come back to it later.
Inside a directory, we have a single configuration file. We will be using terragrunt to keep our code DRY. Also, managing a single file is much easier rather than managing multiple terraform files.
Module structure
Before looking into module structures, let’s spend a minute on what modules are and how we are planning to use them. A module is a collection of resources that can be used without redefining it. If you are from a programming background, think of a function. You define a function that does something; for example, say find the sum of two numbers. And if you want to find the sum of two numbers, you invoke the function with some parameter instead of writing the entire summation logic again.
For core resources such as VPC, DynamoDB, Lambda, etc. We can either use community-written modules. terraform-aws-modules & cloudposse are some of the well known community providers. These are well-tested modules but gives us less control over the module source code.
Another option is writing our modules. We have used this option in the past as it made more sense for us as we wanted more control over the source code and wanted to tweak our modules quickly.
Modules can be defined internally inside the infra repository or externally in a separate GitHub repository. We defined modules in a separate GitHub repository. In the past, we have moved from defining the modules inside the infra directory to a separate GitHub repository, as we wanted to create a versioned release for our modules. Therefore, we pushed the release bundle to S3. This gave us the flexibility to use different versions of the modules and also made them highly available.
We created one API Gateway module with all the terraform resources required for deploying an API Gateway, and we used this module in all our service definitions. In addition, we had defined custom GitHub actions to bundle API Gateway terraform files to the S3 bucket.
If you are writing your modules, use terraform-docs to generate documentation. This makes life easier while using modules as it mentions the required module parameter and output variables.
Also, we wanted to define our service/ apps as modules. We defined them internally, which allowed us to keep the code DRY and resources definition consistent across environments. So a service module consisted of all the required resources such as VPC, Lambda, API gateway, etc.
module "api_gateway" { source = "s3::https://s3.amazonaws.com/buytoys-build-artifacts/terraform-modules/terraform-aws-api-gateway/v1.2.3.zip" name = "${local.service_name}-rest-api" env = var.env tags = local.tags api_gateway_types = var.api_gateway_types service_name = local.service_name enable_api_gw_logging = var.enable_api_gw_logging api_gw_logging_level = var.api_gw_logging_level enable_api_gw_access_logging = var.enable_api_gw_access_logging }
Naming conventions
For naming resources visible in the AWS console, we used a general rule of thumb to use hyphens, and for terraform resource names, we used underscore. So, for example, if you want to create an S3 bucket.
resource aws_s3_bucket dummy_s3_bucket { name = "${var.env}-s3-bucket" ... }
Generally, there are two ways to name a terraform file. Either using specific names that tells the purpose of the file. So, for example: If we want to create an S3 resource, we can define all S3 related resources inside a file and name it s3.tf. It helps other developers to get an idea of the contents of the files without actually looking inside it. Another approach is to use something more generic like the main.tf, it’s helpful if we want to use multiple resources or refer to some terraform modules inside the code.
For naming a directory, if the files inside the directory defines a module, then the directory name should be the module name. If the files inside the directory define a service or app, then it should be named as per service or app name.
Internally, terraform merges all .tf into one large file and run the plan accordingly. So it doesn’t matter what name is given to the file. But, having intuitive file names & directory names based on logical grouping helps understand the infrastructure better and makes it easier for the developer to navigate through the code.
Resource blocks
Now, as we understand how to structure and name our files, let’s spend some time discussing some code-level best practices.
Terraform allows us to use count meta argument to create that many resources. So, for example, the following snippet will create four bastions.
count = 4 ami = "ami-a1b2c3d4" instance_type = "t2.micro" tags = { Name = "Server ${count.index}" } }
It’s advisable to keep the count statement on top rather than at the bottom.
2. Use sensitive = true to mark the output-sensitive; Terraform will hide values that are marked sensitive in terraform plan and terraform apply.
output "bastion_private_key_pem" { value = module.bastion.private_key sensitive = true }
3. Adding default values and proper description to variables.
variable "engine_version" { type = string default = "10.14" description = "Engine version for RDS(postgres)" }
4. Adding tags to resources. Tagging resources can be helping in multiple ways. In the past, we have used it to give granular access to developers based on tags.
Manage Statefile
Statefile is a snapshot of the infrastructure and is used as a source of truth by the terraform to plan and apply infrastructure changes. It’s a JSON file consisting of secrets, passwords, and other sensitive information. It should be handled with extra care and should never be pushed to any VCS like Github.
For keeping your state secure, it’s advisable to use some remote store like S3. A backend such as S3 allows us to encrypt our files in transit and at rest, adding confidence that any secrets stored in our statefile are less susceptible to falling into the wrong hands.
Also, it comes with object versioning which is valuable in understanding and debugging what was changed between each terraform apply if a change negatively impacted our service.
Using remote statefiles is very simple; it requires two things.
A S3 bucket that will be used to store the statefile
To Configuring the backend in terraform.
terraform { backend "s3" { bucket = "my-bucket-name" key = "filename.tfstate" region = "eu-west-2" encrypt = true } }
Also its highly discouraged to modify statefile manually until unless you know what you are doing. It is meant to be used by terraform.
Providers & Terraform versions
Terraform uses provider plugins to interact with cloud providers. Pinning terraform, and provider version is helpful for certainty and visibility.
terraform { required_version = ">= 0.13" required_providers { aws = { source = "hashicorp/aws" version = "~> 3.26.0" } } }
Also to manage multiple version of terraform we have used asdf & tfswitch. These tools make switching between versions very easy.
Now, as we have seen, some of the best practices of terraform. Let’s quickly discuss some caveats and possible workarounds.
Caveats
Upgrading to a newer version of terraform or provider with module dependency. To upgrade the provider version or terraform version, we first need to upgrade the version in the modules. So, for example, onboarding-service uses API Gateway, VPC, DB, and Lambda module. So, to upgrade the version of plugins (terraform, AWS) for onboarding service, we first need to upgrade the plugin version in all dependent modules.
Updating security group name & description is terraform destroy and recreate and not update in place. So, this might cause a problem when you want to update the description of the security group attached to a VPC or a DB, and you can’t delete the DB or the VPC. So, terraform will try to delete the security group and create a new one with an updated description. But, the deletion will fail after 15 mins of retrying and by throwing the
DependencyViolationerror. For updating the description of the security group, we found that using a life-cycle meta-argument was helpful.
resource "aws_security_group" "rds_sg" { vpc_id = var.vpc_id description = "AWS Security group for RDS" ... lifecycle { ignore_changes = [ description, ] } }
3. Sometimes, it might happen that if we are updating some resources, it might lead to downtime. So, for example, renaming a DB master username is such one task. This leads to first destroying the older database and recreate a new database with an updated name. This also leads to the loss of data. So we need to come with some custom solution to handle such scenarios.
Conclusion
You can write terraform code in whatever way that suits you. But it should aid developers in fulfilling their primary goal of providing business value.
So to summarize
Logical grouping of resources and files is essential in navigating the code quickly.
If some piece of code is needed multiple times, it’s better to create a module out of it. To keep it DRY.
Each module should do one thing. Either it can create a usable resource or a service, or an app.
Adding descriptions to variables and outputs helps while calling that module.
If you are working in a large team, setting up a remote backend for terraform is essential to prevent stepping on someone else’s toe.
Modifying statefile manually is like playing with fire. Please do whatever you can to avoid it.
It’s essential to have a code of conduct documented if the team size is large, as it acts as a reference document for the members to follow these unsaid guidelines.
In this post
In this post
Section
Share
Share
In this post
section
Share
Keywords
terraform, terraform best practices, terraform gotchas, infrastructure as code, terraform tips, terraform modules, terraform state management, terraform cloud, terraform workflow, IaC security, terraform mistakes to avoid, terraform automation, terraform variables, terraform remote state, terraform version control, terraform CI CD, terraform beginners, advanced terraform, terraform troubleshooting, terraform guide, cloud infrastructure provisioning, terraform code organization, terraform linting, terraform drifts, terraform one2n










