Context.
The client is a global MSSP (Managed Security Service Provider) company. They host and manage a popular Security Information and Events Management (SIEM) platform for detecting, monitoring, and responding to cybersecurity threats and incidents. Their system handles 100s of tenants and more than 1.5 Terabytes of security events and logs data daily.
Problem Statement.
Provide administrative controls for customizing the backup and restore options
Provide administrative controls for customizing the backup and restore options
Provide administrative controls for customizing the backup and restore options
Build an automated backup and recovery process for the SIEM data
Build an automated backup and recovery process for the SIEM data
Build an automated backup and recovery process for the SIEM data
Implement tenant-wise customizations for data retention, data locality, and other parameters
Implement tenant-wise customizations for data retention, data locality, and other parameters
Implement tenant-wise customizations for data retention, data locality, and other parameters
Outcome/Impact.
1.5TB
1.5TB
1.5TB
Dataset handled daily
Dataset handled daily
Dataset handled daily
100+
100+
100+
tenants using backup restore solution
tenants using backup restore solution
tenants using backup restore solution
$200
$200
$200
Running cost per month
Running cost per month
Running cost per month
Built an automated solution supporting 1.5 terabytes of SIEM data backup per day
Built an automated solution supporting 1.5 terabytes of SIEM data backup per day
Built an automated solution supporting 1.5 terabytes of SIEM data backup per day
Built an automated solution supporting 1.5 terabytes of SIEM data backup per day
The solution supports 100+ tenants for the MSSP
The solution supports 100+ tenants for the MSSP
The solution supports 100+ tenants for the MSSP
The solution supports 100+ tenants for the MSSP
Support automated restore process for any tenant
Support automated restore process for any tenant
Support automated restore process for any tenant
Support automated restore process for any tenant
The entire backup and restore solution costs less than $200 per month to run
The entire backup and restore solution costs less than $200 per month to run
The entire backup and restore solution costs less than $200 per month to run
The entire backup and restore solution costs less than $200 per month to run
The solution was built by just 1 engineer in 4 months
The solution was built by just 1 engineer in 4 months
The solution was built by just 1 engineer in 4 months
The solution was built by just 1 engineer in 4 months
Solution.
The client is a world-leading Managed Security Service Provider (MSSP). Their SIEM software handles threat detection and remediation for 100+ tenant organizations from the healthcare, energy, and finance sectors. They have been in cybersecurity as a service business for over two decades.
The client team deals with about 1.5 Terabytes of SIEM data daily from all tenants. Storing and managing the reliability and availability of this data is a major task. They already had an existing solution for the backup and recovery of this SIEM data. This solution consisted of configuration and events data backup. However, as the business and compliance requirements grew, improving and optimizing the existing solution was needed. They reached out to the One2N team for help.
We have worked extensively with large datasets for B2B use cases and decided to take up this problem. We evaluated the existing backup and recovery system and found that it needed improvements with respect to cost, customizations, and operational needs. We decided to improve this existing system according to business and compliance needs.
We worked closely with the Security Operations and Platform teams to document system requirements as below.
System requirements.
Tenant-wise data separation and retention
Automated backup/restore with minimal manual intervention
Alert on the success/failure of the backup process
Tenant-wise restoration for a custom date range
Centralized backup store with auditing and RBAC
A bit about the SIEM
Here’s some background about the SIEM system:
It consists of two types of machines - Orchestration nodes and Data nodes.
Orchestration nodes store configuration and Data nodes store the actual event and log data. A single tenant belongs to one Data node.
For our setup, we had 2 Orchestration nodes and 24 Data nodes geographically distributed across the data centers.
For the 100+ tenants that the client supports, the total log and event data size was 1.5 Terabytes per day across all Data nodes.
The Backup solution in a nutshell.
To back up the SIEM data, we need to back up two things:
The Configuration data from Orchestration nodes and
Daily events and log data from Data nodes.
Configuration backup was relatively simple as the data size was small (about 5GB per Orchestration node). We configured the SIEM platform to produce a tar file of the configuration and uploaded the file via a simple Bash script to AWS S3.
Data backup was complicated as the backup size could be 200+ GB for a single Data node for a single day’s events. Storing these large files and uploading them over the network was challenging.
Here’s the solution we came up with that fits the requirements and minimizes operational costs.
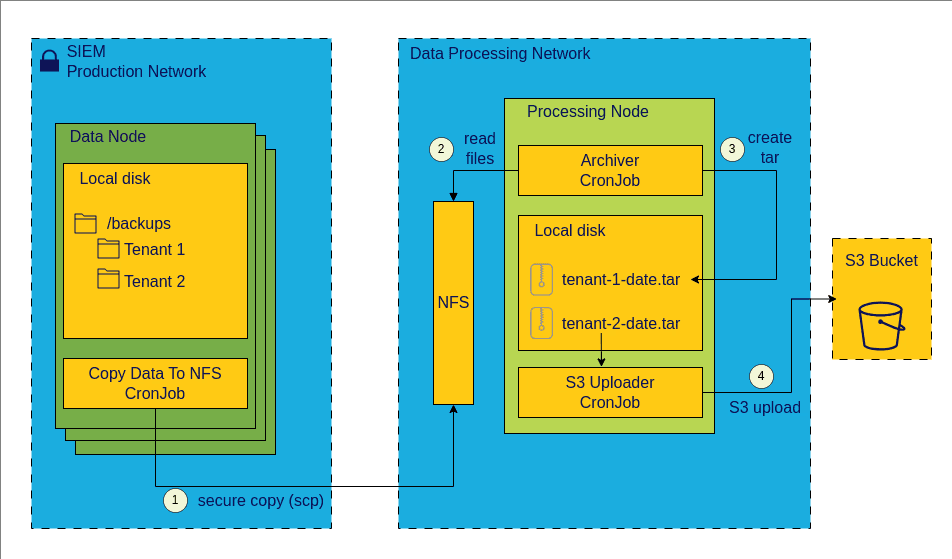
SIEM backup process
Here’s how the backup solution works.
We
scpthe relevant tenant data directories from the Data node to a Network File System (NFS) server.NFS is accessible from the Processing server. We package the directory structure from NFS into a tar file on the Processing server.
We upload the tar files to S3 archival storage and delete the original files and directories from the Processing server and NFS.
This whole process runs as a parallel data pipeline. Thus, each of the operations (scp, tar, and upload to S3) run in parallel as much as possible.
Since we are dealing with large data (1.5 TB per day), we have checks to ensure the disk doesn’t fill up during copying or tar creation.
Challenges encountered
High CPU and disk utilization on Data Nodes
Initially, we tried to run the entire tar + Upload to S3 operation on the Data nodes. However, this resulted in high CPU utilization and an increase in IOPS, causing latency issues in production. Hence, we introduced NFS and Processing server to perform these compute and IO intensive workloads.
Impact on production traffic and latencies
Since we uploaded 1.5 Terabytes of data daily to S3, the production network bandwidth got impacted. To solve this problem, we added limits to network bandwidth usage using the --max_bandwidth flag for S3 CLI when uploading data to S3. We also added a dedicated network pipe just for uploading this data to S3. This allowed us to transfer large data over the wire without impacting production workloads.
Inefficient Data Transfer to S3
Initially, we only uploaded one file at a time to S3. Later, we improved the upload process by parallelizing it with 10 concurrent sessions, leading to more efficient data transfer.
Reducing data storage costs
We used Glacier Deep Archive storage format for event and log data and S3 Standard storage for configuration backup. We configured Lifecycle policies on S3 buckets to delete data beyond the retention period. We also set up appropriate default retention on buckets and enabled object versioning.
Restore process
We developed a script for the data restore that performs the reverse process as the backup script. This restore script fetches data from S3 and copies the directories to the appropriate tenant-wise directory structure.
Deploying the solution in production
The backup and restore solution is deployed across all client regions. It’s been running successfully in production since January 2023 with minimal operational oversight. The total storage cost of S3 Deep Archive is less than $200 per month for the volume of data the client handles.
The client is a world-leading Managed Security Service Provider (MSSP). Their SIEM software handles threat detection and remediation for 100+ tenant organizations from the healthcare, energy, and finance sectors. They have been in cybersecurity as a service business for over two decades.
The client team deals with about 1.5 Terabytes of SIEM data daily from all tenants. Storing and managing the reliability and availability of this data is a major task. They already had an existing solution for the backup and recovery of this SIEM data. This solution consisted of configuration and events data backup. However, as the business and compliance requirements grew, improving and optimizing the existing solution was needed. They reached out to the One2N team for help.
We have worked extensively with large datasets for B2B use cases and decided to take up this problem. We evaluated the existing backup and recovery system and found that it needed improvements with respect to cost, customizations, and operational needs. We decided to improve this existing system according to business and compliance needs.
We worked closely with the Security Operations and Platform teams to document system requirements as below.
System requirements.
Tenant-wise data separation and retention
Automated backup/restore with minimal manual intervention
Alert on the success/failure of the backup process
Tenant-wise restoration for a custom date range
Centralized backup store with auditing and RBAC
A bit about the SIEM
Here’s some background about the SIEM system:
It consists of two types of machines - Orchestration nodes and Data nodes.
Orchestration nodes store configuration and Data nodes store the actual event and log data. A single tenant belongs to one Data node.
For our setup, we had 2 Orchestration nodes and 24 Data nodes geographically distributed across the data centers.
For the 100+ tenants that the client supports, the total log and event data size was 1.5 Terabytes per day across all Data nodes.
The Backup solution in a nutshell.
To back up the SIEM data, we need to back up two things:
The Configuration data from Orchestration nodes and
Daily events and log data from Data nodes.
Configuration backup was relatively simple as the data size was small (about 5GB per Orchestration node). We configured the SIEM platform to produce a tar file of the configuration and uploaded the file via a simple Bash script to AWS S3.
Data backup was complicated as the backup size could be 200+ GB for a single Data node for a single day’s events. Storing these large files and uploading them over the network was challenging.
Here’s the solution we came up with that fits the requirements and minimizes operational costs.
SIEM backup process
Here’s how the backup solution works.
We
scpthe relevant tenant data directories from the Data node to a Network File System (NFS) server.NFS is accessible from the Processing server. We package the directory structure from NFS into a tar file on the Processing server.
We upload the tar files to S3 archival storage and delete the original files and directories from the Processing server and NFS.
This whole process runs as a parallel data pipeline. Thus, each of the operations (scp, tar, and upload to S3) run in parallel as much as possible.
Since we are dealing with large data (1.5 TB per day), we have checks to ensure the disk doesn’t fill up during copying or tar creation.
Challenges encountered
High CPU and disk utilization on Data Nodes
Initially, we tried to run the entire tar + Upload to S3 operation on the Data nodes. However, this resulted in high CPU utilization and an increase in IOPS, causing latency issues in production. Hence, we introduced NFS and Processing server to perform these compute and IO intensive workloads.
Impact on production traffic and latencies
Since we uploaded 1.5 Terabytes of data daily to S3, the production network bandwidth got impacted. To solve this problem, we added limits to network bandwidth usage using the --max_bandwidth flag for S3 CLI when uploading data to S3. We also added a dedicated network pipe just for uploading this data to S3. This allowed us to transfer large data over the wire without impacting production workloads.
Inefficient Data Transfer to S3
Initially, we only uploaded one file at a time to S3. Later, we improved the upload process by parallelizing it with 10 concurrent sessions, leading to more efficient data transfer.
Reducing data storage costs
We used Glacier Deep Archive storage format for event and log data and S3 Standard storage for configuration backup. We configured Lifecycle policies on S3 buckets to delete data beyond the retention period. We also set up appropriate default retention on buckets and enabled object versioning.
Restore process
We developed a script for the data restore that performs the reverse process as the backup script. This restore script fetches data from S3 and copies the directories to the appropriate tenant-wise directory structure.
Deploying the solution in production
The backup and restore solution is deployed across all client regions. It’s been running successfully in production since January 2023 with minimal operational oversight. The total storage cost of S3 Deep Archive is less than $200 per month for the volume of data the client handles.













