Context.
Flip is a fintech company in Indonesia. We migrated their stateless services running on 25+ VMs in the Alibaba cloud to their managed Kubernetes offering (ACK).
These application services served Flip's B2B and B2C traffic which often peaked at 25,000 requests/second.
Problem Statement.
Implement autoscaling of the infrastructure to handle peak traffic.
Implement autoscaling of the infrastructure to handle peak traffic.
Implement autoscaling of the infrastructure to handle peak traffic.
Move to a Cloud-Native architecture to use modern tooling.
Move to a Cloud-Native architecture to use modern tooling.
Move to a Cloud-Native architecture to use modern tooling.
Outcome/Impact.
30%
30%
30%
Cost Saved
Cost Saved
Cost Saved
120
120
120
Pods at peak load
Pods at peak load
Pods at peak load
0sec
0sec
0sec
Downtime
Downtime
Downtime

The entire migration took 3 months. The major challenge was to map the existing complex Nginx configuration to maintainable Ingress resources in Kubernetes.
The entire migration took 3 months. The major challenge was to map the existing complex Nginx configuration to maintainable Ingress resources in Kubernetes.
The entire migration took 3 months. The major challenge was to map the existing complex Nginx configuration to maintainable Ingress resources in Kubernetes.
The entire migration took 3 months. The major challenge was to map the existing complex Nginx configuration to maintainable Ingress resources in Kubernetes.
The overall process was transparent to the user and carried out without downtime or business impact.
The overall process was transparent to the user and carried out without downtime or business impact.
The overall process was transparent to the user and carried out without downtime or business impact.
The overall process was transparent to the user and carried out without downtime or business impact.
Solution.
The existing setup consisted of web and mobile apps accessing backend APIs running on Alibaba Cloud VMs. The user traffic was routed via Cloudflare. Each VM had Nginx and PHP-FPM processes. The SRE team managed the scaling of infra to serve the traffic accordingly.
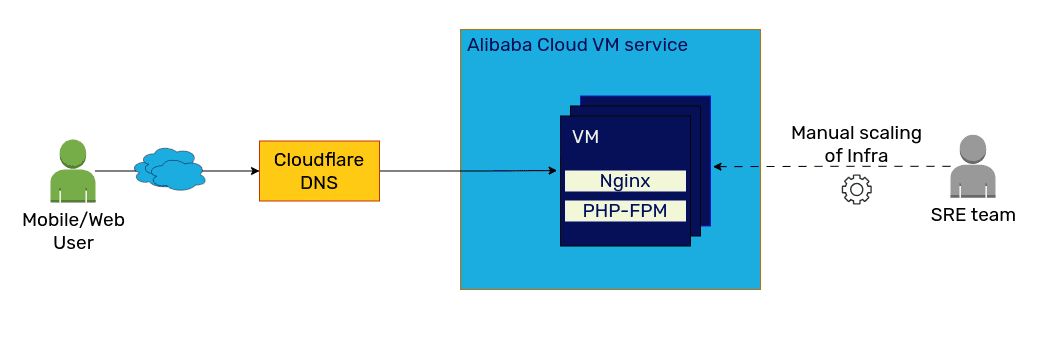
Existing VM based setup
Making the application cloud native.
We started with containerizing the application. We separated the tightly coupled Nginx and PHP-FPM processes into separate stateless containers. One backend service used a sticky session, so we worked with the dev team to make it stateless.
We migrated the existing Nginx configuration and routing rules to a ConfigMap in Kubernetes. We used the PHP container as Sidecar to Nginx in the same pod and mounted the ConfigMap.
We also introduced ConfigMap reloader to detect config changes and automatically reload the application without downtime. This saved us operational overhead.
From the security perspective, we adopted cloud-native secrets management and restricted access to the SRE team in production.
Flip being a Fintech, reliability is of utmost priority. We updated the Continuous Deployment process to do Canary and controlled rollout to production. That way, we could detect errors before they impact all users.
The cloud-native architecture allowed us to quickly set up observability tools to provide better visibility into operations.We also used the Kubernetes Horizontal Pod Autoscaler (HPA) to automate the scaling in/out of the Pods based on the traffic reducing the operation toil. So overall system looked as below.
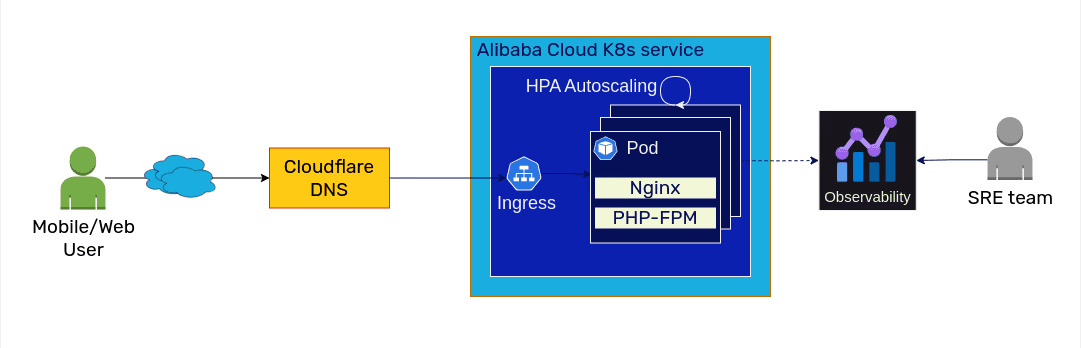
Application setup on kubernetes
Gradual traffic movement from VMs to Kubernetes.
To ensure no users are impacted, we ran both VM and Kubernetes setup in parallel and gradually migrated all the traffic from VMs to Kubernetes. We updated the deployment pipeline to deploy the application to both VM and Kubernetes setup in parallel.We were already using Cloudflare for DNS and DDoS protection. So, we decided to use Cloudflare’s External Load Balancer to migrate the traffic from the VM to Kubernetes.We started routing 10% of live traffic to the Kubernetes setup. We monitored RED metrics to make sure we don’t breach the SLO.Within 3 weeks, we could move 100% of the traffic to Kubernetes. We then decommissioned the VM setup. During this time, there was no business impact and the entire migration happened transparently to the users.During the entire migration period, the product team kept shipping new features and we deployed these features on both VM and Kubernetes environments.
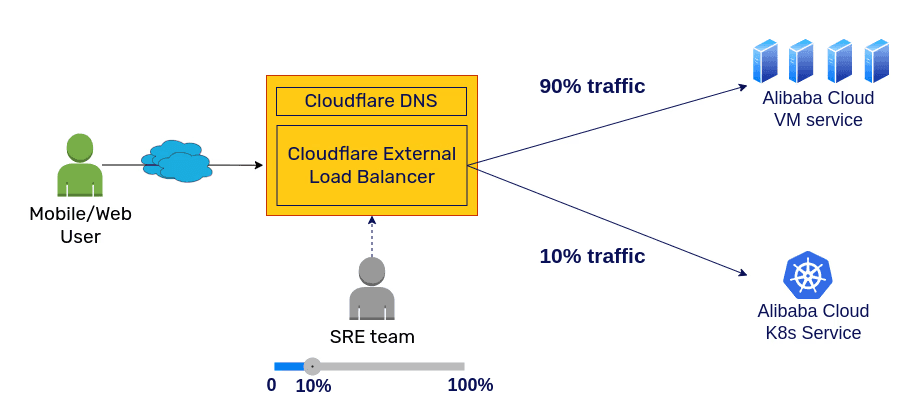
Phased rollout using Cloudflare external load balancer
Managing the reliability at scale.
Initially, during sudden peak loads, the application often faced higher latencies, sometimes resulting in gateway timeout and business impact.The manual scaling of VMs was time-consuming and human-dependent. It was error-prone, and it took substantial time for a new VM to be ready to accept user requests.We used Horizontal Pod Autoscaler (HPA) to scale down by 70% during non-peak hours, saving 30% cost on compute resources.In case of additional load, the HPA would automatically kick in and scale the capacity without human intervention. We observed the number of pods reaching 120 during the peak load.
Tech stack used.



The existing setup consisted of web and mobile apps accessing backend APIs running on Alibaba Cloud VMs. The user traffic was routed via Cloudflare. Each VM had Nginx and PHP-FPM processes. The SRE team managed the scaling of infra to serve the traffic accordingly.
Existing VM based setup
Making the application cloud native.
We started with containerizing the application. We separated the tightly coupled Nginx and PHP-FPM processes into separate stateless containers. One backend service used a sticky session, so we worked with the dev team to make it stateless.
We migrated the existing Nginx configuration and routing rules to a ConfigMap in Kubernetes. We used the PHP container as Sidecar to Nginx in the same pod and mounted the ConfigMap.
We also introduced ConfigMap reloader to detect config changes and automatically reload the application without downtime. This saved us operational overhead.
From the security perspective, we adopted cloud-native secrets management and restricted access to the SRE team in production.
Flip being a Fintech, reliability is of utmost priority. We updated the Continuous Deployment process to do Canary and controlled rollout to production. That way, we could detect errors before they impact all users.
The cloud-native architecture allowed us to quickly set up observability tools to provide better visibility into operations.We also used the Kubernetes Horizontal Pod Autoscaler (HPA) to automate the scaling in/out of the Pods based on the traffic reducing the operation toil. So overall system looked as below.
Application setup on kubernetes
Gradual traffic movement from VMs to Kubernetes.
To ensure no users are impacted, we ran both VM and Kubernetes setup in parallel and gradually migrated all the traffic from VMs to Kubernetes. We updated the deployment pipeline to deploy the application to both VM and Kubernetes setup in parallel.We were already using Cloudflare for DNS and DDoS protection. So, we decided to use Cloudflare’s External Load Balancer to migrate the traffic from the VM to Kubernetes.We started routing 10% of live traffic to the Kubernetes setup. We monitored RED metrics to make sure we don’t breach the SLO.Within 3 weeks, we could move 100% of the traffic to Kubernetes. We then decommissioned the VM setup. During this time, there was no business impact and the entire migration happened transparently to the users.During the entire migration period, the product team kept shipping new features and we deployed these features on both VM and Kubernetes environments.
Phased rollout using Cloudflare external load balancer
Managing the reliability at scale.
Initially, during sudden peak loads, the application often faced higher latencies, sometimes resulting in gateway timeout and business impact.The manual scaling of VMs was time-consuming and human-dependent. It was error-prone, and it took substantial time for a new VM to be ready to accept user requests.We used Horizontal Pod Autoscaler (HPA) to scale down by 70% during non-peak hours, saving 30% cost on compute resources.In case of additional load, the HPA would automatically kick in and scale the capacity without human intervention. We observed the number of pods reaching 120 during the peak load.
Tech stack used.













