Context.
Flip is a fintech company in Indonesia. They used self-managed MySQL as the database. The schema migrations worked well until their transaction volume was small. However, as the database tables grew in size, schema changes and index management became problematic. Some of the tables were huge, and adding a small integer column resulted in write locks and downtime for the main service.
Problem Statement.
DB schema migrations on large tables (400+ million rows or 150+ GB in size for a single table) caused replication lag and impacted latencies.
DB schema migrations on large tables (400+ million rows or 150+ GB in size for a single table) caused replication lag and impacted latencies.
DB schema migrations on large tables (400+ million rows or 150+ GB in size for a single table) caused replication lag and impacted latencies.
Adding indexes on large tables also resulted in replication lag and degraded query performance.
Adding indexes on large tables also resulted in replication lag and degraded query performance.
Adding indexes on large tables also resulted in replication lag and degraded query performance.
Outcome/Impact.
400M rows
400M rows
400M rows
Biggest table migrated
Biggest table migrated
Biggest table migrated
7
7
7
migrations per month
migrations per month
migrations per month
0sec
0sec
0sec
Downtime due to schema migrations
Downtime due to schema migrations
Downtime due to schema migrations

Developers were able to execute schema changes and index modifications without any downtime.
Developers were able to execute schema changes and index modifications without any downtime.
Developers were able to execute schema changes and index modifications without any downtime.
Developers were able to execute schema changes and index modifications without any downtime.
Developers could iterate on product features faster as they weren't blocked due to schema migration changes.
Developers could iterate on product features faster as they weren't blocked due to schema migration changes.
Developers could iterate on product features faster as they weren't blocked due to schema migration changes.
Developers could iterate on product features faster as they weren't blocked due to schema migration changes.
We didn't face replication lag or MySQL thread spikes during schema migrations.
We didn't face replication lag or MySQL thread spikes during schema migrations.
We didn't face replication lag or MySQL thread spikes during schema migrations.
We didn't face replication lag or MySQL thread spikes during schema migrations.
Solution.
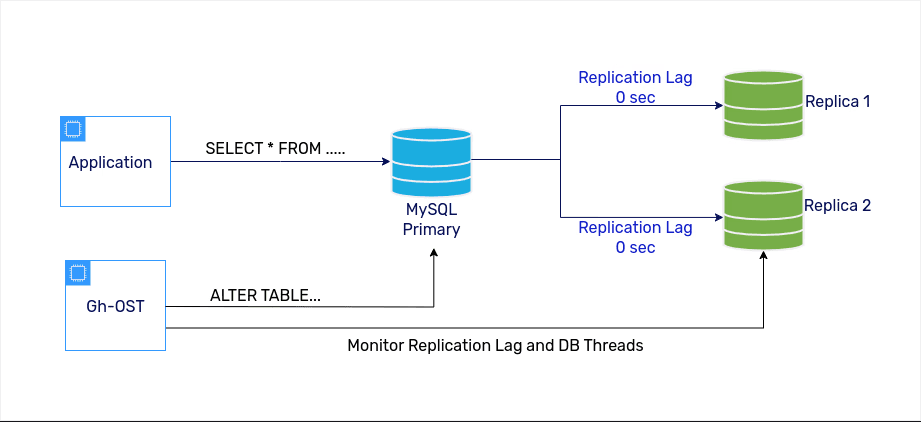
The existing database setup was a MySQL 5.7 primary instance and two read-only replica instances.


Any schema migration operation on a large table (e.g., alter table to add a new column) results in replication lag on all replicas, causing data inconsistency and higher latencies for all queries.
MySQL 5.7 doesn't support online schema migration without causing replication lag and other issues. While the table sizes were small, we did not encounter this issue. However, as the transaction volume and table sizes grew beyond a few million rows per table, we couldn't execute alter table queries directly on the primary database. Our database had a scale of 14,000 read queries per second, and 4500 write queries per second. Hence, even 1 second of replication lag would impact many users and queries.
This was the challenge that we wanted to solve.
We evaluated two popular tools that work around this limitation of MySQL. They are:
pt-osc from Percona Toolkit and
gh-ost from GitHub
Why we chose gh-ost over pt-osc.
For both of these tools, the core idea is the same. We create a shadow (empty) table with desired characteristics. It includes the correct columns and indexes. Then the tool will copy the rows from the original live table to the shadow table. It will keep the tables in sync and swap the shadow and live tables. A quick comparison is below.
pt-osc | gh-ost |
|---|---|
Trigger based | Binary log based streaming replication |
Synchronous, rows are copied as part of the same transaction | Asynchronous, rows are copied independently of the current transaction |
Data copy can be throttled, but not the triggers | Data copy can be throttled dynamically |
Preparing for production rollout.
We set up a replica of the production environment where we would try out gh-ost and its various configuration options for our use case.
We found that the following flags were most crucial for us.
Threads_running: The active threads on the primary database server
Max-lag-millis: The current replication lag on the replicas
When these thresholds are crossed, gh-ost will throttle the copying operation. Apart from this, we also used a two-step manual postponed cutover to have control over the switchover. The actual command we used for migration is as below.
$ gh-ost --user="" --password="" --host="" --allow-on-master --database="" --table="" --verbose --alter="" --initially-drop-ghost-table --initially-drop-old-table --max-load=Threads_running=10 --chunk-size=500 --concurrent-rowcount --postpone-cut-over-flag-file=.postpone.flag --throttle-control-replicas="," --max-lag-millis=2000 --cut-over=two-step --serve-socket-file=gh-ost.test.sock --panic-flag-file=gh-ost.panic.flag --execute > table-name.log
$ gh-ost --user="" --password="" --host="" --allow-on-master --database="" --table="" --verbose --alter="" --initially-drop-ghost-table --initially-drop-old-table --max-load=Threads_running=10 --chunk-size=500 --concurrent-rowcount --postpone-cut-over-flag-file=.postpone.flag --throttle-control-replicas="," --max-lag-millis=2000 --cut-over=two-step --serve-socket-file=gh-ost.test.sock --panic-flag-file=gh-ost.panic.flag --execute > table-name.log
Gh-OST in production
We created internal documentation and policies after successfully testing gh-ost for our scale. These policies govern when and how to use gh-ost and where it fits in the CI/CD process.
We have used gh-ost in production for more than 100s of the schema changes, and it has worked reliably. We often do multiple schema changes in the same run for faster rollouts.
Tech stack used.



The existing database setup was a MySQL 5.7 primary instance and two read-only replica instances.
Any schema migration operation on a large table (e.g., alter table to add a new column) results in replication lag on all replicas, causing data inconsistency and higher latencies for all queries.
MySQL 5.7 doesn't support online schema migration without causing replication lag and other issues. While the table sizes were small, we did not encounter this issue. However, as the transaction volume and table sizes grew beyond a few million rows per table, we couldn't execute alter table queries directly on the primary database. Our database had a scale of 14,000 read queries per second, and 4500 write queries per second. Hence, even 1 second of replication lag would impact many users and queries.
This was the challenge that we wanted to solve.
We evaluated two popular tools that work around this limitation of MySQL. They are:
pt-osc from Percona Toolkit and
gh-ost from GitHub
Why we chose gh-ost over pt-osc.
For both of these tools, the core idea is the same. We create a shadow (empty) table with desired characteristics. It includes the correct columns and indexes. Then the tool will copy the rows from the original live table to the shadow table. It will keep the tables in sync and swap the shadow and live tables. A quick comparison is below.
pt-osc | gh-ost |
|---|---|
Trigger based | Binary log based streaming replication |
Synchronous, rows are copied as part of the same transaction | Asynchronous, rows are copied independently of the current transaction |
Data copy can be throttled, but not the triggers | Data copy can be throttled dynamically |
Preparing for production rollout.
We set up a replica of the production environment where we would try out gh-ost and its various configuration options for our use case.
We found that the following flags were most crucial for us.
Threads_running: The active threads on the primary database server
Max-lag-millis: The current replication lag on the replicas
When these thresholds are crossed, gh-ost will throttle the copying operation. Apart from this, we also used a two-step manual postponed cutover to have control over the switchover. The actual command we used for migration is as below.
$ gh-ost --user="" --password="" --host="" --allow-on-master --database="" --table="" --verbose --alter="" --initially-drop-ghost-table --initially-drop-old-table --max-load=Threads_running=10 --chunk-size=500 --concurrent-rowcount --postpone-cut-over-flag-file=.postpone.flag --throttle-control-replicas="," --max-lag-millis=2000 --cut-over=two-step --serve-socket-file=gh-ost.test.sock --panic-flag-file=gh-ost.panic.flag --execute > table-name.log
Gh-OST in production
We created internal documentation and policies after successfully testing gh-ost for our scale. These policies govern when and how to use gh-ost and where it fits in the CI/CD process.
We have used gh-ost in production for more than 100s of the schema changes, and it has worked reliably. We often do multiple schema changes in the same run for faster rollouts.
Tech stack used.
The existing database setup was a MySQL 5.7 primary instance and two read-only replica instances.
Any schema migration operation on a large table (e.g., alter table to add a new column) results in replication lag on all replicas, causing data inconsistency and higher latencies for all queries.
MySQL 5.7 doesn't support online schema migration without causing replication lag and other issues. While the table sizes were small, we did not encounter this issue. However, as the transaction volume and table sizes grew beyond a few million rows per table, we couldn't execute alter table queries directly on the primary database. Our database had a scale of 14,000 read queries per second, and 4500 write queries per second. Hence, even 1 second of replication lag would impact many users and queries.
This was the challenge that we wanted to solve.
We evaluated two popular tools that work around this limitation of MySQL. They are:
pt-osc from Percona Toolkit and
gh-ost from GitHub
Why we chose gh-ost over pt-osc.
For both of these tools, the core idea is the same. We create a shadow (empty) table with desired characteristics. It includes the correct columns and indexes. Then the tool will copy the rows from the original live table to the shadow table. It will keep the tables in sync and swap the shadow and live tables. A quick comparison is below.
pt-osc | gh-ost |
|---|---|
Trigger based | Binary log based streaming replication |
Synchronous, rows are copied as part of the same transaction | Asynchronous, rows are copied independently of the current transaction |
Data copy can be throttled, but not the triggers | Data copy can be throttled dynamically |
Preparing for production rollout.
We set up a replica of the production environment where we would try out gh-ost and its various configuration options for our use case.
We found that the following flags were most crucial for us.
Threads_running: The active threads on the primary database server
Max-lag-millis: The current replication lag on the replicas
When these thresholds are crossed, gh-ost will throttle the copying operation. Apart from this, we also used a two-step manual postponed cutover to have control over the switchover. The actual command we used for migration is as below.
$ gh-ost --user="" --password="" --host="" --allow-on-master --database="" --table="" --verbose --alter="" --initially-drop-ghost-table --initially-drop-old-table --max-load=Threads_running=10 --chunk-size=500 --concurrent-rowcount --postpone-cut-over-flag-file=.postpone.flag --throttle-control-replicas="," --max-lag-millis=2000 --cut-over=two-step --serve-socket-file=gh-ost.test.sock --panic-flag-file=gh-ost.panic.flag --execute > table-name.log
Gh-OST in production
We created internal documentation and policies after successfully testing gh-ost for our scale. These policies govern when and how to use gh-ost and where it fits in the CI/CD process.
We have used gh-ost in production for more than 100s of the schema changes, and it has worked reliably. We often do multiple schema changes in the same run for faster rollouts.
Tech stack used.
The existing database setup was a MySQL 5.7 primary instance and two read-only replica instances.
Any schema migration operation on a large table (e.g., alter table to add a new column) results in replication lag on all replicas, causing data inconsistency and higher latencies for all queries.
MySQL 5.7 doesn't support online schema migration without causing replication lag and other issues. While the table sizes were small, we did not encounter this issue. However, as the transaction volume and table sizes grew beyond a few million rows per table, we couldn't execute alter table queries directly on the primary database. Our database had a scale of 14,000 read queries per second, and 4500 write queries per second. Hence, even 1 second of replication lag would impact many users and queries.
This was the challenge that we wanted to solve.
We evaluated two popular tools that work around this limitation of MySQL. They are:
pt-osc from Percona Toolkit and
gh-ost from GitHub
Why we chose gh-ost over pt-osc.
For both of these tools, the core idea is the same. We create a shadow (empty) table with desired characteristics. It includes the correct columns and indexes. Then the tool will copy the rows from the original live table to the shadow table. It will keep the tables in sync and swap the shadow and live tables. A quick comparison is below.
pt-osc | gh-ost |
|---|---|
Trigger based | Binary log based streaming replication |
Synchronous, rows are copied as part of the same transaction | Asynchronous, rows are copied independently of the current transaction |
Data copy can be throttled, but not the triggers | Data copy can be throttled dynamically |
Preparing for production rollout.
We set up a replica of the production environment where we would try out gh-ost and its various configuration options for our use case.
We found that the following flags were most crucial for us.
Threads_running: The active threads on the primary database server
Max-lag-millis: The current replication lag on the replicas
When these thresholds are crossed, gh-ost will throttle the copying operation. Apart from this, we also used a two-step manual postponed cutover to have control over the switchover. The actual command we used for migration is as below.
$ gh-ost --user="" --password="" --host="" --allow-on-master --database="" --table="" --verbose --alter="" --initially-drop-ghost-table --initially-drop-old-table --max-load=Threads_running=10 --chunk-size=500 --concurrent-rowcount --postpone-cut-over-flag-file=.postpone.flag --throttle-control-replicas="," --max-lag-millis=2000 --cut-over=two-step --serve-socket-file=gh-ost.test.sock --panic-flag-file=gh-ost.panic.flag --execute > table-name.log
Gh-OST in production
We created internal documentation and policies after successfully testing gh-ost for our scale. These policies govern when and how to use gh-ost and where it fits in the CI/CD process.
We have used gh-ost in production for more than 100s of the schema changes, and it has worked reliably. We often do multiple schema changes in the same run for faster rollouts.
Tech stack used.













