
A curious story of debugging Machine Learning model performance
You're woken up by a p90 latency-related alert.
This alert is for the main API service, so you start investigating right away.
Your first thought is: it was working well so far, what changed - deployment or config. Hours later, you'd find out that it was neither.
Storytime
You're a team lead handling the entire backend engineering at a growing Series A org. The org provides B2B SaaS APIs and SDKs for an online KYC (Know Your Customer) use case. The SaaS has been in production for 6+ months, but this is the first time a p90 latency alert is fired.
Your natural instinct as an SRE is to ask two questions:
Was it working before?
What changed to cause it to fail?
You know that:
past 6+ months, no latency issues. You're not sure why this alert now?
Recently, there haven't been any deployments or config changes.
🤔🤔🤔
So, you open the observability dashboards. The main eKYC APIs that use the Machine Learning models in the background are slow. These APIs are responsible for face matching and parsing ID card info.
These are the most critical APIs for the business.
Debugging
You start a war room and ask team members to join in. While the team members join, you're trying to find out what could have caused this latency?
Could it be
Image store (Minio)
Redis (cached results)
API server itself
or Database (PostgreSQL)
or RabbitMQ
ML workers
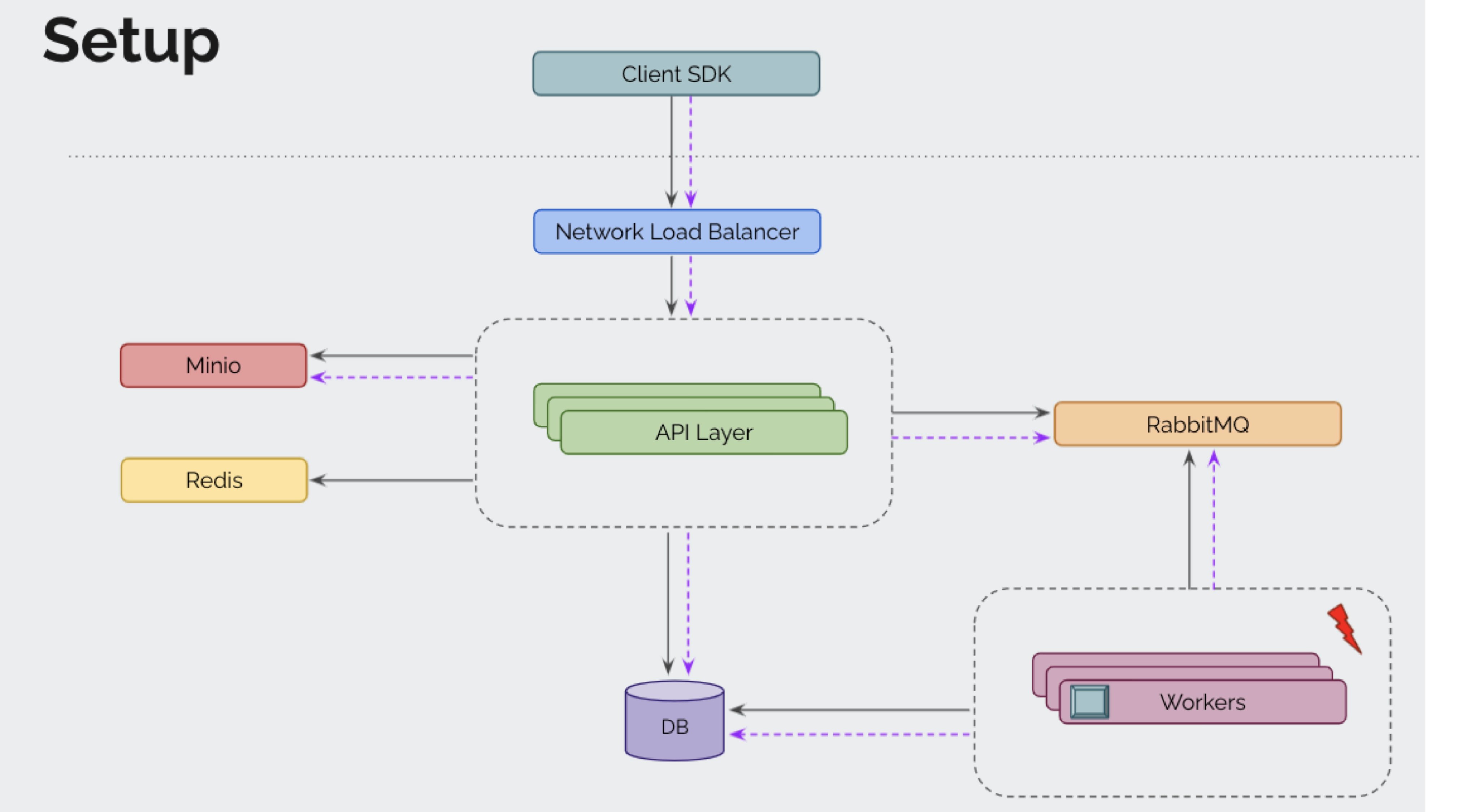
There's no tracing but the request flow is:
client SDK to API
API sends a message to RabbitMQ
ML worker does processing
ML worker sends a response back on RabbitMQ
API layer picks up the response and returns it to the user.
DB, Redis, and Minio are involved in relevant layers.
In all your load testing so far, the ML workers have been the bottleneck. Since there hasn't been any deployment or config change, you focus your attention on the latency for the ML workers. You load up that dashboard only to find out a few 100ms response times for ML workers.
"It's very normal"
You say this to yourself, as the p90 latency for ML workers has always been < 2 seconds. So why is there a 20+ second latency for the APIs? The load on the system in the past few weeks has been consistently increasing.
Maybe it's the DB, Minio, or RabbitMQ?
You check DB dashboards, queries per second, latencies, CPU/memory utilization, etc. You ask other folks in the war room to check similar metrics for Minio, RabbitMQ, Redis, etc. You're looking for any clues where things could be broken/slow.
A couple of hours pass, nothing gives.
You're exhausted.
You did load testing for 10x the scale on prod earlier, and it was all working fine back then. Why this problem now?
"Has something changed in the ML model? Is someone checking API server metrics?"
You ask in the war room, but you're running out of ideas.
You want some time for yourself to think. Just when you decide to pass on the baton to someone else in the war room, the CEO joins the call. You quickly brief him and tell him that you've already initiated a process to inform customers. It's not SLA breach yet, but may soon be.
You take a 5-minute break to clear your head. Drink some water, force yourself to look at trees.
"I can't do nothing at this point, I couldn't take the break."
You say this as you join the war room again, barely a minute since you left.
A ray of hope
The struggle to find and fix the cause continues for a few more minutes. At this point, all collective ideas have been tried, and the war room is silent. Everyone's tired. A backend engineer unmutes amid what seems like an eternity of silence.
"I think I may have found it. It's probably RabbitMQ and API workers"
Before they can complete their thought, someone else interjects:
"But, we have been through this, there's no latency on ML workers. Also, all queues related to ML Workers have almost zero queue depth".
You stop them from shunning the backend engineer.
"Let's hear him out" you say. The engineer continues:
"Agree that the ML workers have no latency issue. But I was going through all rabbitMQ queues and I see that the API worker queue is stuck. You see, the ML workers process the request and send the response back to another RabbitMQ queue. The workers on the API side then fetch from this queue and return the response to the user."
"Yeah, so?" someone interjects again.
The engineer continues:
"So, I think there are not enough workers to process these messages on the API side. That's why we don't see any latency on any of the other components, be it ML workers, database, minio, redis, etc. I saw the worker count on API, It's just 3. We should increase it to 50 or more. I know I am asking for a config change and a deployment in the middle of a major incident, but I think this is the issue."
You nod reluctantly as you're still thinking about whether this could really be the issue.
You take a few seconds to think. You can't find any flaws in the logic. And the metrics and data seem to also check out. You suggest to go ahead with this change. And sure enough, right as the deployment finishes, the latency drops back to normal, just like that!
"How did we not look at these RabbitMQ queues"
You ask.
There's silence. But then one engineer replies:
"We never thought this could be a culprit, so we only added monitoring for queues for ML Workers. After all, during all our load testing, we never saw this problem. During load testing, we only tested individual components, not the whole end-to-end system, as it was too much effort. that's why we never realized the API worker count could be an issue. After all, the only thing the API workers do is take the data and send it back to the user"
Lessons
There's so much to learn from this incident. One could say:
you don't have tracing, so you asked for it.
you don't have end-to-end monitoring, what do you expect?
and many more.
While these are certainly things to fix and improve, I personally learned something that day.
It's that:
Bugs will be found where your assumptions break.
If you go with a preconceived notion in debugging a system, it will bite you hard.
We assumed the issue would be on ML workers and focused all our energy on trying to find a bug there and missed something obvious.
Real life debugging is pretty messy. The more situations you have to debug, the better you become. Debugging is as much a mindset and thought process skill as it is a technical skill.
If you need help with scaling machine learning workloads, DM me. We ultimately scaled these models to 2 Million+ API requests per day. And never had these issues again.
This was one of the reasons I started One2N - to help growing orgs scale sustainably.
I write such stories on software engineering.
There's no specific frequency, as I don't make these up.
If you liked this one, you might love - My app is slow. Can you fix it?
Follow me on LinkedIn and Twitter for more such stuff, straight from the production oven!





