Context.
The client provides cloud and on-premise based Hospital Management Services (HMS) SaaS platform. This HMS serves 800+ B2B customers (tenants), including large hospital chains across the Middle East, Africa, and APAC region. The tech stack for the application is a Java-based backend, JSP-based server rendered UI, Redis, and MySQL as datastores. The HMS platform is deployed as a SaaS and in customers' cloud environments and on-premise data centers.
Problem Statement.
Improving Observability: Setup centralized cloud-agnostic observability stack to enable platform-wide monitoring with the ability to enable per-tenant monitoring
Improving Observability: Setup centralized cloud-agnostic observability stack to enable platform-wide monitoring with the ability to enable per-tenant monitoring
Improving Observability: Setup centralized cloud-agnostic observability stack to enable platform-wide monitoring with the ability to enable per-tenant monitoring
Deployment automation: Improve the application release process to reduce the deployment time across SaaS and customer environments.
Deployment automation: Improve the application release process to reduce the deployment time across SaaS and customer environments.
Deployment automation: Improve the application release process to reduce the deployment time across SaaS and customer environments.
Outcome/Impact.
Setup a single pane of observability for the client team to monitor all their customer environments.
Setup a single pane of observability for the client team to monitor all their customer environments.
Setup a single pane of observability for the client team to monitor all their customer environments.
Setup a single pane of observability for the client team to monitor all their customer environments.
Set up per customer observability so that support team can debug application and infrastructure problems.
Set up per customer observability so that support team can debug application and infrastructure problems.
Set up per customer observability so that support team can debug application and infrastructure problems.
Set up per customer observability so that support team can debug application and infrastructure problems.
Contanerise the application, enable Continuous Integration workflow, and implement GitOps-based deployments.
Contanerise the application, enable Continuous Integration workflow, and implement GitOps-based deployments.
Contanerise the application, enable Continuous Integration workflow, and implement GitOps-based deployments.
Contanerise the application, enable Continuous Integration workflow, and implement GitOps-based deployments.
Bring down deployment time from days to a few minutes.
Bring down deployment time from days to a few minutes.
Bring down deployment time from days to a few minutes.
Bring down deployment time from days to a few minutes.
Solution.
The HMS is deployed in one of two ways:
A SaaS solution hosted and managed by the client team
An on-premise solution hosted at the customer site (cloud and data centers) and managed by the client team
When One2N team started the work, there were two major challenges we set out to solve:
Set up the observability stack for all environments
Improve the application release processLet’s look at these in detail.
Set up Observability.
Let’s answer some foundational questions like:
Why centralized observability was needed?
What did we do?
How did we set it up?
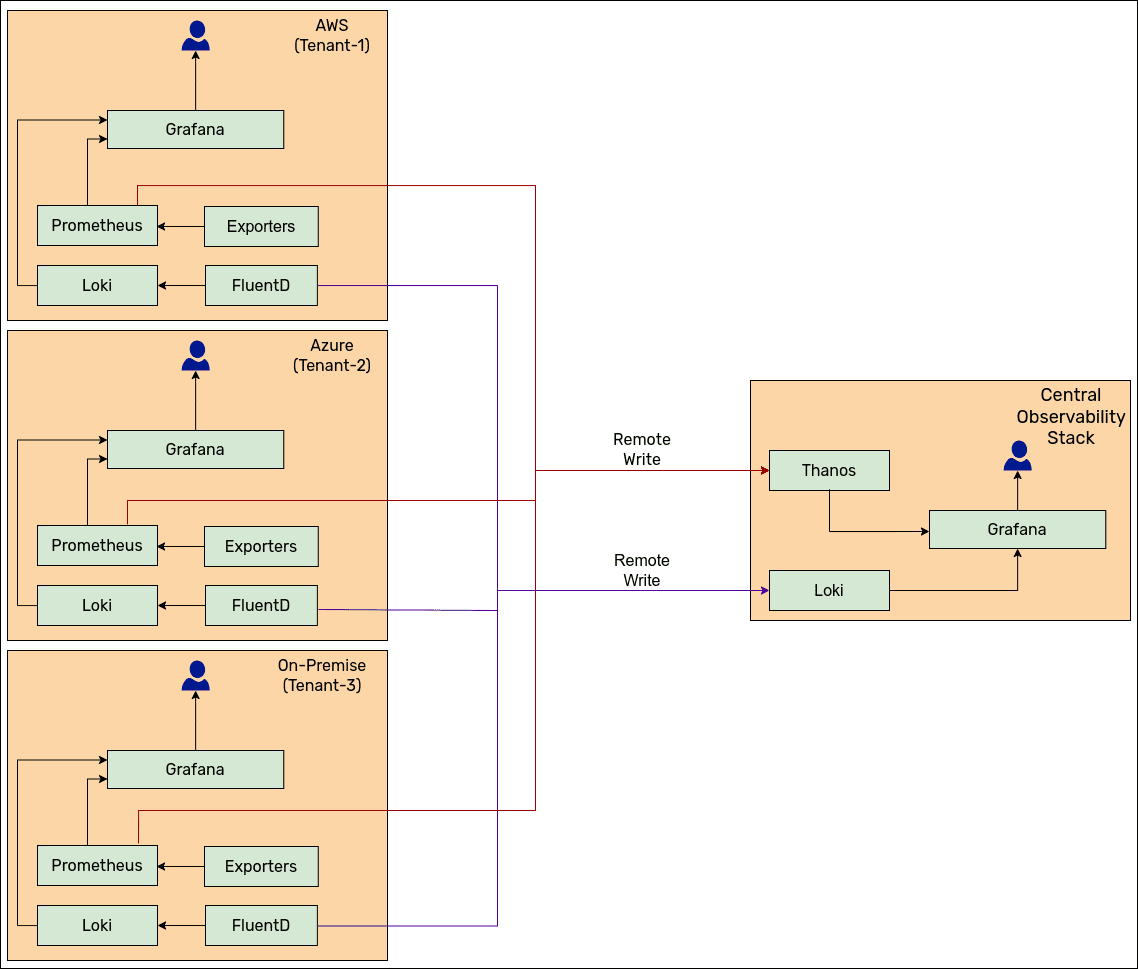
Client's Observability Setup
Why: The client team wanted a single pane to observe all the environments, including SaaS and customer environments. Without this, the client team would always be reactive and know about the problems only when customers reported them. The goal of a centralized observability system is to help the client team be more proactive in understanding system failures.
What: We evaluated the build-vs-buy option by performing a proof of concept for a centralized observability SaaS solution (e.g., Newrelic). However, we decided not to proceed with this due to the outgoing data costs it would incur (to send the logs and metrics to the centralized monitoring stack outside of the cloud environment). We couldn’t use a cloud-specific solution (e.g., AWS Cloudwatch) since some deployments were also on other clouds (e.g., Azure). Hence, we needed a self-hosted monitoring solution that’s based on open-source tooling.
How: For a homogenous, self-hosted observability solution across all environments, we finally settled on Prometheus, Fluentd, Loki, Grafana, and Thanos stack. Each client would have its own Prometheus, Loki, and Grafana stack, where client teams would look at dashboards and alerts. Logs and metrics were also pushed to the central Loki and Thanos setup via remote write. This way, the client team had access to monitoring data for all clients.
Based on each of the customer’s deployment setup and SLO needs, we rolled out this solution via Helm chart deployments or systemd services. We ensured the monitoring infra setup is separate from the application setup so that when/if production goes down, the monitoring infra doesn’t go down with it. On the client side, we deployed the monitoring stack via Helm charts. We also automated the creation of various infrastructure and application dashboards so that each client doesn’t have to create these dashboards themselves.
This centralized observability solution has been deployed on all environments and has been actively used by developers and system administrators.
Let’s now look at how we solved some challenges related to the application release process.
Improve the application release process.
For improving the application release process, we started with improving the local dev setup and application packaging. Here are some challenges we solved in the process.
Challenge 1: The application was stateful and had many heterogeneous environments.
The applications weren’t designed to be run in a stateless (and distributed) manner. The app used stateful HTTP sessions tied to a single server IP. We worked with the dev team to find and fix these issues. They updated the app to run in a stateless manner so that we can horizontally scale the API layer by running the same app on multiple instances. The stateful sessions had to be moved to cache (Redis).
Almost all the production environments were unique in their own way. These environments were treated as pets instead of cattle. To solve this problem, we containerized the application to run anywhere without custom scripting. For this, we worked with the dev team to apply the 12-factor app principles of separating config from code. We removed the hardcoded config from the code and moved it as part of the environment that can be passed during the application run. We created multiple dockerfiles that compiled the backend and frontend code using multi-stage docker builds. In the end, we optimized the container image size to be about 600Mb from an earlier size of about 2GB.
Challenge 2: Ad-hoc deployment automation.
The deployment scripts used to deploy the app were tied to Ubuntu OS. These ad-hoc scripts grew in lines and complexity with time. The existing scripts had a lot of dead code with conditional logic (e.g., to support older application releases). Imagine 1000+ lines of bash scripting logic to build and deploy the app.
We standardized the deployment automation across all environments. For production deployments, we used Kubernetes, Helm, and ArgoCD. For non-prod environments, we created an Ansible playbook that deployed the latest docker image from the dev branch onto the test server. This helped the QA team quickly deploy and test new application changes without getting overwhelmed with Kubernetes tooling. For running DB schema migrations, we used init containers in Kubernetes.
In summary, we were able to roll out this whole solution (Observability and Application Release Process improvements) across all of the client's B2B customers over a period of one year.
The HMS is deployed in one of two ways:
A SaaS solution hosted and managed by the client team
An on-premise solution hosted at the customer site (cloud and data centers) and managed by the client team
When One2N team started the work, there were two major challenges we set out to solve:
Set up the observability stack for all environments
Improve the application release processLet’s look at these in detail.
Set up Observability.
Let’s answer some foundational questions like:
Why centralized observability was needed?
What did we do?
How did we set it up?
Client's Observability Setup
Why: The client team wanted a single pane to observe all the environments, including SaaS and customer environments. Without this, the client team would always be reactive and know about the problems only when customers reported them. The goal of a centralized observability system is to help the client team be more proactive in understanding system failures.
What: We evaluated the build-vs-buy option by performing a proof of concept for a centralized observability SaaS solution (e.g., Newrelic). However, we decided not to proceed with this due to the outgoing data costs it would incur (to send the logs and metrics to the centralized monitoring stack outside of the cloud environment). We couldn’t use a cloud-specific solution (e.g., AWS Cloudwatch) since some deployments were also on other clouds (e.g., Azure). Hence, we needed a self-hosted monitoring solution that’s based on open-source tooling.
How: For a homogenous, self-hosted observability solution across all environments, we finally settled on Prometheus, Fluentd, Loki, Grafana, and Thanos stack. Each client would have its own Prometheus, Loki, and Grafana stack, where client teams would look at dashboards and alerts. Logs and metrics were also pushed to the central Loki and Thanos setup via remote write. This way, the client team had access to monitoring data for all clients.
Based on each of the customer’s deployment setup and SLO needs, we rolled out this solution via Helm chart deployments or systemd services. We ensured the monitoring infra setup is separate from the application setup so that when/if production goes down, the monitoring infra doesn’t go down with it. On the client side, we deployed the monitoring stack via Helm charts. We also automated the creation of various infrastructure and application dashboards so that each client doesn’t have to create these dashboards themselves.
This centralized observability solution has been deployed on all environments and has been actively used by developers and system administrators.
Let’s now look at how we solved some challenges related to the application release process.
Improve the application release process.
For improving the application release process, we started with improving the local dev setup and application packaging. Here are some challenges we solved in the process.
Challenge 1: The application was stateful and had many heterogeneous environments.
The applications weren’t designed to be run in a stateless (and distributed) manner. The app used stateful HTTP sessions tied to a single server IP. We worked with the dev team to find and fix these issues. They updated the app to run in a stateless manner so that we can horizontally scale the API layer by running the same app on multiple instances. The stateful sessions had to be moved to cache (Redis).
Almost all the production environments were unique in their own way. These environments were treated as pets instead of cattle. To solve this problem, we containerized the application to run anywhere without custom scripting. For this, we worked with the dev team to apply the 12-factor app principles of separating config from code. We removed the hardcoded config from the code and moved it as part of the environment that can be passed during the application run. We created multiple dockerfiles that compiled the backend and frontend code using multi-stage docker builds. In the end, we optimized the container image size to be about 600Mb from an earlier size of about 2GB.
Challenge 2: Ad-hoc deployment automation.
The deployment scripts used to deploy the app were tied to Ubuntu OS. These ad-hoc scripts grew in lines and complexity with time. The existing scripts had a lot of dead code with conditional logic (e.g., to support older application releases). Imagine 1000+ lines of bash scripting logic to build and deploy the app.
We standardized the deployment automation across all environments. For production deployments, we used Kubernetes, Helm, and ArgoCD. For non-prod environments, we created an Ansible playbook that deployed the latest docker image from the dev branch onto the test server. This helped the QA team quickly deploy and test new application changes without getting overwhelmed with Kubernetes tooling. For running DB schema migrations, we used init containers in Kubernetes.
In summary, we were able to roll out this whole solution (Observability and Application Release Process improvements) across all of the client's B2B customers over a period of one year.












