
Context.
Flip is a fintech company in Indonesia. Their primary MySQL database was self-managed and self-hosted on a cloud provider. They were looking to move away from that cloud provider to GCP and wanted to migrate the self-hosted MySQL setup to GCP’s CloudSQL. MySQL server received the peak traffic of 10,000 database requests per second, and the total database size was 1.3 Terabytes.
Problem Statement.
Migrate from a self-hosted MySQL cluster containing three nodes in a Primary/Replica setup to a GCP CloudSQL setup. As a fintech company data, the downtime has to be minimal without sacrificing data consistency, integrity and durability, and overall adherence to the organization's SLA.
Outcome/Impact.

Solution.
The below diagram shows the initial setup. It consisted of the applications run as Pods. These Pods point to the ProxySQL High Availability Cluster. This cluster routes all the write queries to the MySQL Primary and Read queries to the MySQL read replicas. The read replicas are in sync using binary logs. The SRE team managed each MySQL server node.
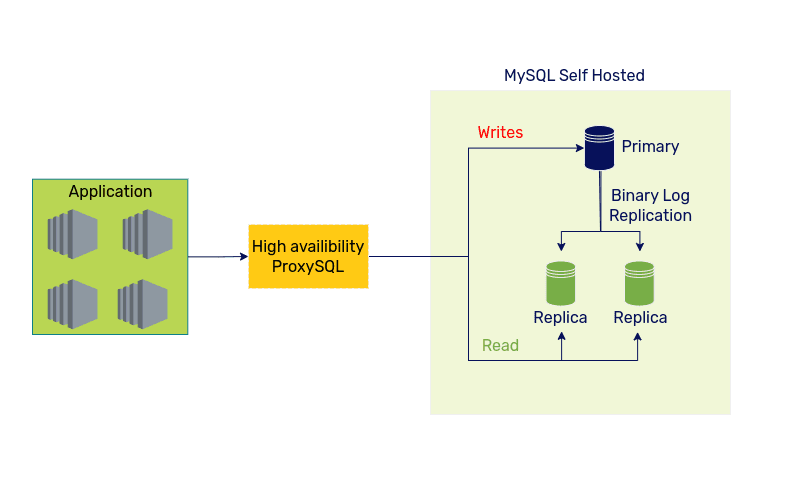
Existing self-hosted MySQL setup
We evaluated different options to migrate data from MySQL to CloudSQL. It includes
Point in-time backup and restore
GCP Data Migration Service (DMS) with support for continuous replication
CloudSQL External Replication
After comparing these options, we found DMS to be easy to set up, uses native binary logs for replication, and comes with monitoring of the data lag and data copied.
We found a few downsides with DMS.
DMS itself provisions the CloudSQL instances. So we could not use Terraform. But we could later import it.
CloudSQL Primary instance provisioned is in replica mode and not HA. It blocks read/writes when promoting the Instance as Primary. We had planned for a small window of downtime that involves promoting.
DMS could not reach the source MySQL primary in another Cloud Provider even though we had set up VPC peering. We had to set up some IPtables NAT rules to work around it.
DMS runs large
Select * …statements on the entire table, which causes writes to be blocked, affecting the DB performance for huge tables. So to work around that, we used a read-only replica with binary logs enabled as the source for DMS.
We started the DMS a couple of days before D-Day, and it took around three days to copy 1.3TB data, and the DMS replication lag came towards 0. At this point, the CloudSQL replica was in sync with the primary MySQL.
For the cutover
We had put all customer-facing apps in maintenance mode to indicate an easy-to-understand response to users.
We were already using ProxySQL for our read/write workload separation, so we used it to our advantage to simplify the cutover process. We reduced the write weights to ensure that internal apps are not writing to the primary database. We added a backend host entry for CloudSQL and adjusted the weights during cutover to move the traffic from hosted MySQL to CloudSQL.
Once basic read/write was working and tested with internal apps, we provisioned more CloudSQL replicas to match our original cluster size and updated ProxySQL to add the new read replica entries.
On a high level, the cutover process looked like below
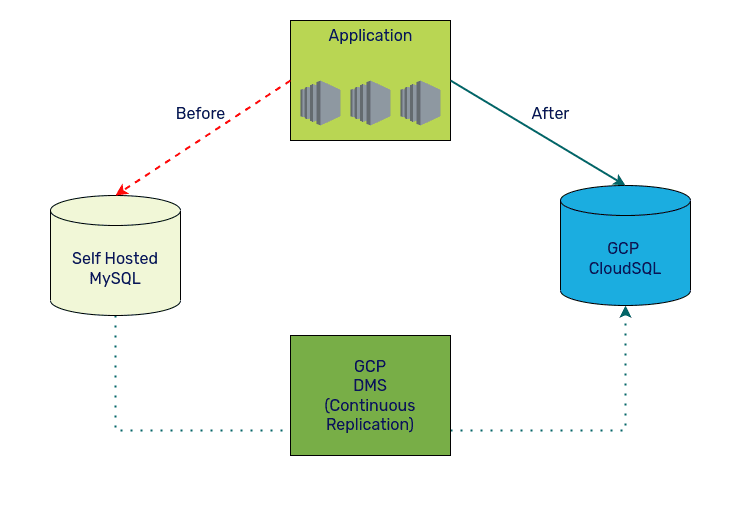
Cutover process
After the production traffic was served successfully, we observed frequent tiny spikes of replication lags. We tuned the Innodb_flush_log_at_trx_commit flag. CloudSQL also supports Parallel replication, but the flag worked great enough for us that we decided to enable parallel replication later in the future.
We also observed that the GCP Cloud Monitoring metrics do not represent the true values of the metrics, such as replication lag, so we ended up setting up a native MySQL agent (Datadog in our case) which would connect to CloudSQL over MySQL connection to get most accurate values which we used to set up alerts.
Once the cutover was complete, the final setup looked as below. The application pods connected to ProxySQL HA setup, routing the Write queries to CloudSQL Primary and Read questions to the CloudSQL read replicas.
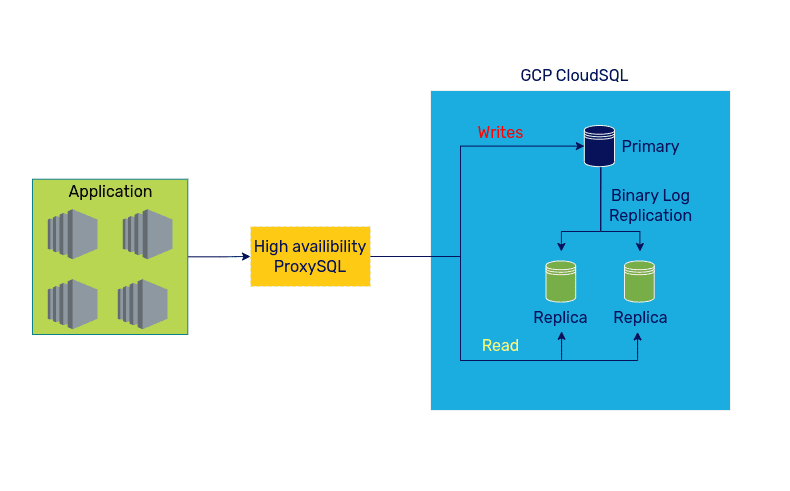
New GCP CloudSQL setup
The entire migration process took two months, including planning for MySQL and other stateless workloads for a team of 4 engineers. We migrated the stateless services without any downtime. MySQL was the most challenging part of the overall journey. We achieved the MySQL migration with a mere 10 minutes of downtime.
Tech stack used.




















