
Database Reliability - Migrating Terabyte from self-hosted MySQL to GCP CloudSQL
You're a lead SRE and CTO asks you to manage and scale a self-managed 6-node MySQL cluster with 1.5+ TB data on production.
You do what it takes, a few months pass, but now, it's time to move to a managed service.
You think this should be straightforward, but it's not so easy.
Context
For context, the DB receives 25k reads and 8k writes per second during peak traffic. It's an OLTP database with over 200+ tables. This is the main database for the monolithic app. So far, the team has been self-managing it, but we got good cloud credits, so let's move to GCP.
You list down some requirements:
This is a transactional datastore, so downtime has to be minimum
Data consistency and integrity must be maintained
Org's SLAs have to be met during the migration period
There should be a rollback strategy in case things go wrong
Existing setup
Here's the existing setup.
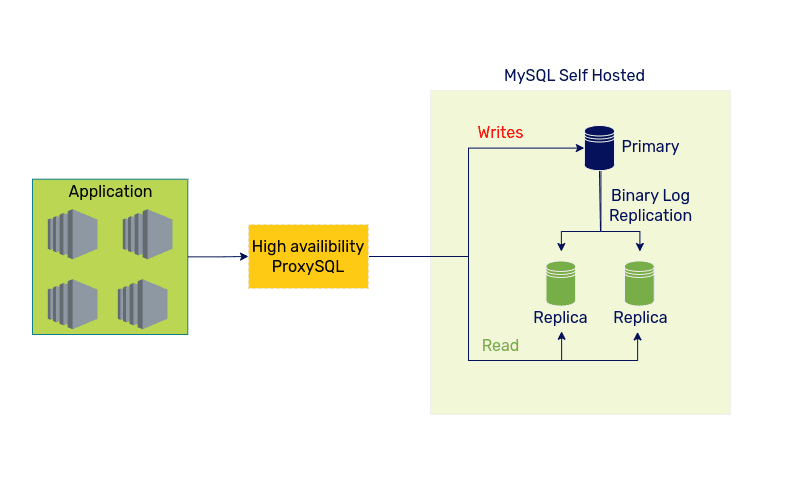
Applications running on Kubernetes connect to ProxySQL. ProxySQL, in turn, splits the read and write traffic based on query rules and weightage configured. The underlying MySQL Primary handles all write traffic, and the Replicas handle read traffic.
Migration Options and Trade-offs
To migrate this database to GCP's CloudSQL, you evaluate three approaches.
Point-in-time backup and restore
GCP Data Migration Service (DMS) with support for continuous replication
CloudSQL External Replication
You compare the pros and cons of each approach.
Point-in-time backup won't work since we can't stop ongoing writes and want minimum downtime.
DMS is easy to set up, uses native binlog replication, and has good monitoring support.
CloudSQL External replication had some prerequisites that our DB didn't meet. So, no.
Final approach
You decided to go ahead with DMS. However, DMS has some downsides:
DMS provisions CloudSQL Primary instance in replica mode and not in high-availability mode. This means reads/writes will be blocked when promoting the instance as Primary.
DMS could not reach the source MySQL primary in another cloud provider even though you had set up VPC peering. To fix this, you set up some IPtables NAT rules so that the DMS service can reach the source MySQL nodes.
DMS runs large select * queries on the entire table to copy the data. To avoid DB perf issues, you had to provision an extra read replica that DMS can replicate from. This way, the source primary isn't overloaded with many parallel table scans.
With all the planning and testing done on the staging environment, you're ready for production migration. It takes 3 days to copy all data from source MySQL to CloudSQL via DMS. Finally, the replication lag is zero, and you're ready for the cutover.
So your cutover plan is:
Put the web app in Maintenance mode (during low traffic time). This will stop write traffic to DB.
Make the CloudSQL node Primary
Move traffic (via ProxySQL) to CloudSQL
Remove maintenance mode and allow all writes to GCP's CloudSQL
So you execute this, and it works as expected (no surprises, which is a good thing). As an SRE, you sometimes doubt things more if these work without any problem. So you double-check the details and data checksum - all good.
Your rigorous testing on staging paid off.
You monitor the whole system during high-traffic times the next day. There are frequent replica lag spikes, so you tweak some MySQL config settings, and these issues are solved. Thankfully, since you have managed self-hosted MySQL, you know what parameters to tune.
Total downtime (maintenance mode time, not the complete downtime) is just 10 minutes, that too during low traffic time.
The CTO and the rest of the business team are pretty happy with this migration. Now that you don't have to manage the uptime for DB, you take a week's vacation.
I write such stories on software engineering.
There's no specific frequency, as I don't make these up.
If you liked this one, you might love - Database Reliability - Zero Downtime Schema Migrations with MySQL
Follow me on LinkedIn and Twitter for more such stuff, straight from the production oven!
Oh, by the way, if you need help with database reliability and scaling, reach out on Twitter or LinkedIn via DMs. We have worked at Terabyte scale when it comes to relational and non-relational databases.
This was one of the reasons I started One2N - to help growing orgs scale sustainably.





