
Not all debugging stories have a happy ending
Sometimes you have to decide what problems are worth solving and only focus on those.
Here's the story:
You migrate application services running on VMs to K8s. Everything works fine, except for one service.
What's going on?
This is a receipt generation service. It generates a receipt of a financial transaction in an image format.
For this, it uses wkhtmltoimage to generate an image from an HTML page. The image is returned as part of the response and users can save the receipt image for later.
Okay, what's the problem when migrating the service to K8s?
The p90 and above latencies.
How bad is the problem?
When the user traffic is served from the code running on VMs, p90 latencies are below 300ms. For the same code, latencies from K8s are 3 sec.
10x difference!
Are you sure it's the same code and the same config?
Yes
Have you dockerized the image correctly?
Yes
Is the infra setup on VMs and K8s similar?
Yes
Are there any external components involved in K8s that are not present on VMs?
No
You ask yourself these questions...
Since you have done many such migrations before, you follow the most important rule for any migration:
"Make it backward compatible and don't YOLO the migration to the new setup."
Always ensure the old solution is still running and slowly migrate traffic to the new solution.
So, the request flow for this service is as follows:
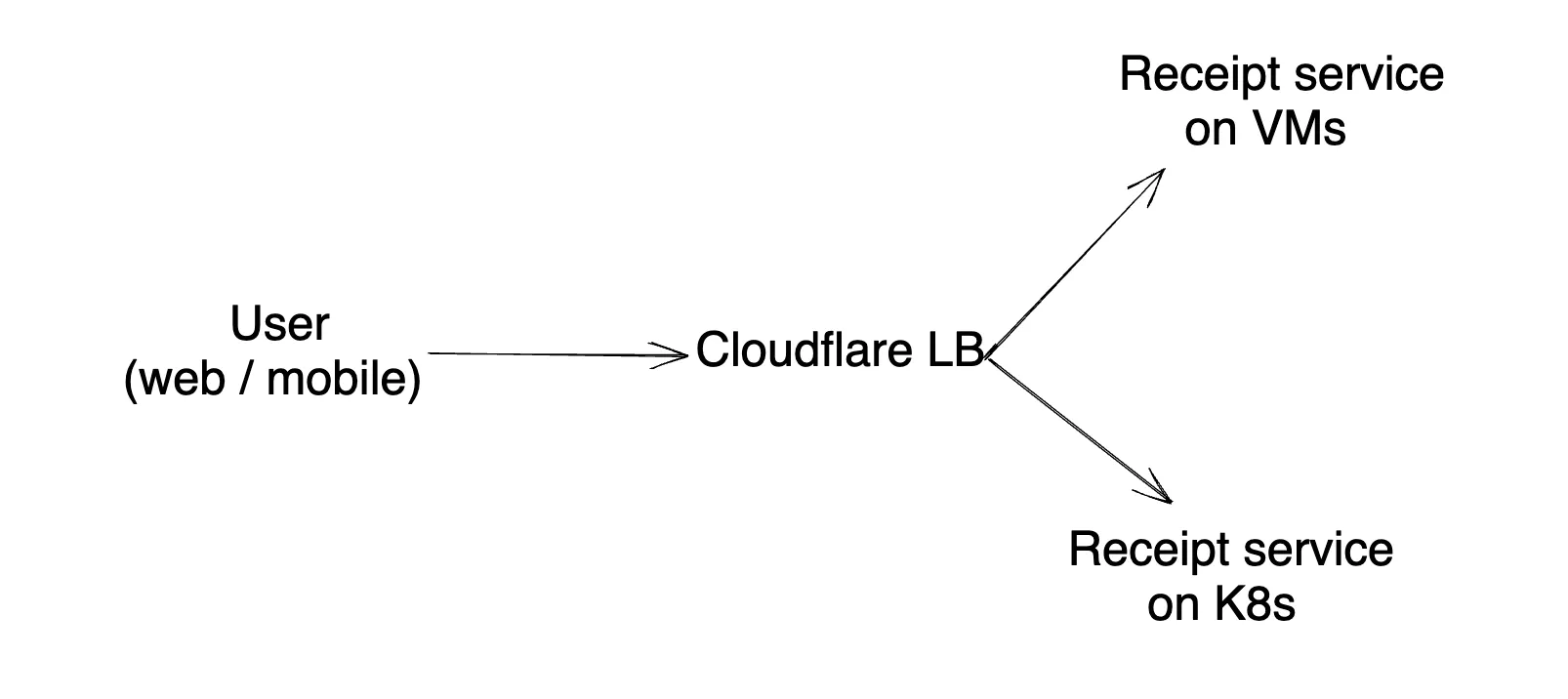
You can control the traffic distribution to the old (VM) setup and new (K8s) set up at the Cloudflare LB level.
Btw, the DB for both receipt services is the same, so you can easily load balance the traffic (stateless APIs)
You update Cloudflare LB config to send 5% of traffic to K8s service. Things are going well, no spike in 5xx errors, latencies are normal, and nothing unusual.
You wait for some time and send 10% of traffic to K8s. You keep repeating this while observing the system.
At about 25%, you notice CPU utilization going up on K8s pods and nodes. The last 5 min avg is touching 60%.
You also notice that:
K8s API latencies > VM API latencies
by a factor of 2-4x.
You re-route traffic from K8s back to VMs and things are normal again.
Fast forwarding:
You run htop on containers to debug what's causing high CPU utilization
You take a look at the code and try to understand the issue
You try to find out the API request rate at which K8s service latencies start degrading
etc...
But the pattern repeats.
Send more traffic to K8s and latencies start increasing, and CPU utilization starts touching 90%.
You also try increasing pod memory and CPU limits, this doesn't help much.
You add some debug logs to know which part of the code is running slow on K8s.
You notice that the receipt generation service runs an `exec` to launch `wkhtmltoimage` in a separate process.
`wkhtmltoimage` then writes the output to a file and the code reads this file and returns the response to the user. The code then deletes this temp file.
From your logs, you conclude that, on K8s, this `exec` takes more time than on VM. You're not sure why.
You try to find if there's any perf penalty if you exec multiple processes on docker. You try to find out if there is any difference in VM vs K8s setup. Nothing stands out.
At this point, you have spent a couple of weeks debugging this issue while still migrating other services and supporting other operational needs, and handling incidents.
You're not sure how much more time you should invest in solving this problem.
As a team, this is when you decide:
"Although this is an interesting technical problem to debug and solve, the value of solving it is not justified.
We'd rather spend our energy in solving other important problems.
Let this service continue to run on VMs."
If it ain't broke, don't fix it. Spend your energy on solving problems that:
either save money for the company or
make more money for the company
As engineers, we have an itch to solve all problems.
This incident taught me to focus my energy and solve problems that matter.
I warned you earlier, this story doesn't have a happy ending.
We still haven't figured out why K8s latencies are higher.
We have 3 VMs on which this service runs and it just works. No fuss. No incident for this service for more than a year.
It's not broken, so let's not fix it.
I write such stories on software engineering. There's no specific frequency as I don't make up these. If you liked this one, you might love - A curious case of slow APIs
Follow me on LinkedIn and Twitter for more such stuff.





