Context.
The client provides eKYC SaaS APIs (face matching, OCR, etc) accessible via Android SDK to its B2B customers. This was deployed for a major Telecom in India and needed to scale up to 2 Million API requests per day.
The tech stack consisted of a Golang-based API, Python-based Machine Learning models, a Message queue (RabbitMQ), Distributed blob storage (Minio) and PostgreSQL DB deployed via docker on Google Cloud using Hashicorp toolchain (Nomad, Consul).
Problem Statement.
Cost optimization. During the pilot phase, cloud costs were $5k per month. For go live, the expected traffic was 20 to 30x of pilot traffic. Here, the cost of GPU VMs (for ML workloads) was a dominating factor (90% share). This would have pushed the cloud costs to $100k per month without auto-scaling.
Cost optimization. During the pilot phase, cloud costs were $5k per month. For go live, the expected traffic was 20 to 30x of pilot traffic. Here, the cost of GPU VMs (for ML workloads) was a dominating factor (90% share). This would have pushed the cloud costs to $100k per month without auto-scaling.
Cost optimization. During the pilot phase, cloud costs were $5k per month. For go live, the expected traffic was 20 to 30x of pilot traffic. Here, the cost of GPU VMs (for ML workloads) was a dominating factor (90% share). This would have pushed the cloud costs to $100k per month without auto-scaling.
Ensuring 99% availability of services during business hours (8 am-10 pm).
Ensuring 99% availability of services during business hours (8 am-10 pm).
Ensuring 99% availability of services during business hours (8 am-10 pm).
Outcome/Impact.
Cloud monthly costs were reduced to a maximum of $10k per month (90% savings over predicted costs without the Autoscaler).
Cloud monthly costs were reduced to a maximum of $10k per month (90% savings over predicted costs without the Autoscaler).
Cloud monthly costs were reduced to a maximum of $10k per month (90% savings over predicted costs without the Autoscaler).
Cloud monthly costs were reduced to a maximum of $10k per month (90% savings over predicted costs without the Autoscaler).
The solution has been live and running successfully on production for 2+ years.
The solution has been live and running successfully on production for 2+ years.
The solution has been live and running successfully on production for 2+ years.
The solution has been live and running successfully on production for 2+ years.
Solution.
In the final Auto Scaling solution, we needed a manual override option. At that time, both Nomad and Kubernetes did not provide this capability out of the box. Also, migrating to Kubernetes would have meant much rework for the entire team. Hence, we decided to build a custom auto-scaling solution on top of Nomad and existing toolchains used in the project.
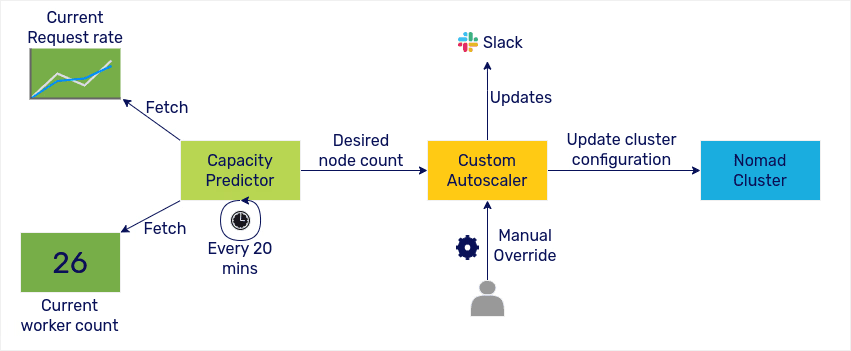
Autoscaler runs every 20 minutes, predicts the traffic for the next cycle and ensures that required ML workers are available. Same logic works for scale up as well as scale down.
Some of the other challenges we encountered were as follows:
Eliminate single points of failure
Run RabbitMQ in High Availability mode with queue replication across three zones in GCP.
Use GCloud Storage as a fallback for Minio. If Minio is unavailable, the application will transparently use GCloud Storage as an image store.
ML workers were split across two availability zones in an odd-even fashion.
For other components (PostgreSQL, Redis, API), we used SaaS offerings by GCP and ran redundant versions of those components.
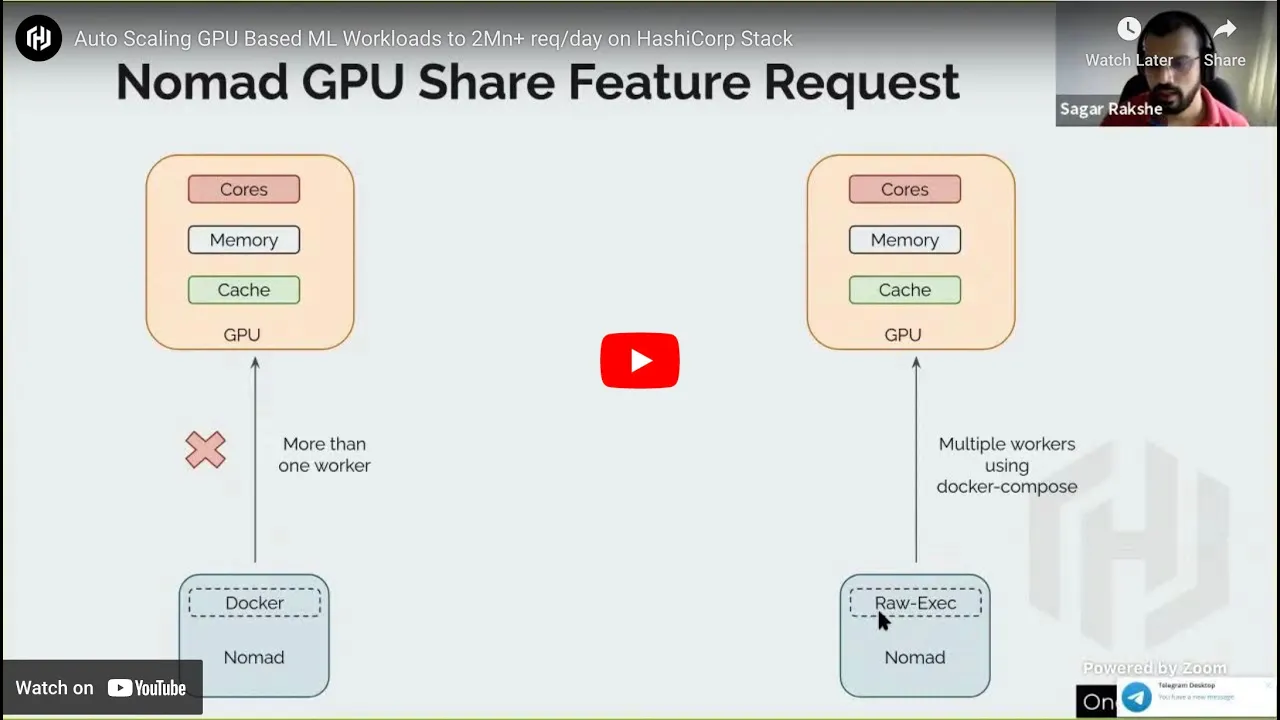
GPU utilization bug in Nomad (https://github.com/hashicorp/nomad/issues/6708)
We used Raw Exec driver from Nomad and launched multiple ML containers on a single VM using docker-compose.
We also implemented custom health checks and CPU stickiness for individual containers.
Capacity Planning
We figured out the optimal VM setup considering factors like GPU, RAM, and cost per hour.
We studied past request patterns and figured out a simple formula for predicting traffic based on a slope of the request growth line.
Automated Rolling Deployments during peak time
We pre-fetched the ML worker docker images (7GB+) on nodes to have a faster startup time during deployments.
The golden image would be updated on the first node. After it is successfully deployed, it would be updated on all remaining nodes, one at a time. This allowed us to deploy services even during peak load.
Monitoring, Alerting, and auto-healing
We made various SLI reports and latency dashboards available to all stakeholders.
Setup PagerDuty and on-call schedules.
Implemented scripted actions for common operation issues (example: Handling Live VM migration for GPU VMs)
Test the whole setup and fix issues
We Performed extensive, long-running Load tests with production-like traffic patterns to ensure the Autoscaler worked as expected.
Tested redundancies and HA setup by introducing chaos (shutting down of nodes and services like Minio) during load testing.
Tech stack used.






Watch this talk for a detailed understanding of the work, presented at HashiTalks India 2021.
In the final Auto Scaling solution, we needed a manual override option. At that time, both Nomad and Kubernetes did not provide this capability out of the box. Also, migrating to Kubernetes would have meant much rework for the entire team. Hence, we decided to build a custom auto-scaling solution on top of Nomad and existing toolchains used in the project.
Autoscaler runs every 20 minutes, predicts the traffic for the next cycle and ensures that required ML workers are available. Same logic works for scale up as well as scale down.
Some of the other challenges we encountered were as follows:
Eliminate single points of failure
Run RabbitMQ in High Availability mode with queue replication across three zones in GCP.
Use GCloud Storage as a fallback for Minio. If Minio is unavailable, the application will transparently use GCloud Storage as an image store.
ML workers were split across two availability zones in an odd-even fashion.
For other components (PostgreSQL, Redis, API), we used SaaS offerings by GCP and ran redundant versions of those components.
GPU utilization bug in Nomad (https://github.com/hashicorp/nomad/issues/6708)
We used Raw Exec driver from Nomad and launched multiple ML containers on a single VM using docker-compose.
We also implemented custom health checks and CPU stickiness for individual containers.
Capacity Planning
We figured out the optimal VM setup considering factors like GPU, RAM, and cost per hour.
We studied past request patterns and figured out a simple formula for predicting traffic based on a slope of the request growth line.
Automated Rolling Deployments during peak time
We pre-fetched the ML worker docker images (7GB+) on nodes to have a faster startup time during deployments.
The golden image would be updated on the first node. After it is successfully deployed, it would be updated on all remaining nodes, one at a time. This allowed us to deploy services even during peak load.
Monitoring, Alerting, and auto-healing
We made various SLI reports and latency dashboards available to all stakeholders.
Setup PagerDuty and on-call schedules.
Implemented scripted actions for common operation issues (example: Handling Live VM migration for GPU VMs)
Test the whole setup and fix issues
We Performed extensive, long-running Load tests with production-like traffic patterns to ensure the Autoscaler worked as expected.
Tested redundancies and HA setup by introducing chaos (shutting down of nodes and services like Minio) during load testing.
Tech stack used.
Watch this talk for a detailed understanding of the work, presented at HashiTalks India 2021.
In the final Auto Scaling solution, we needed a manual override option. At that time, both Nomad and Kubernetes did not provide this capability out of the box. Also, migrating to Kubernetes would have meant much rework for the entire team. Hence, we decided to build a custom auto-scaling solution on top of Nomad and existing toolchains used in the project.
Autoscaler runs every 20 minutes, predicts the traffic for the next cycle and ensures that required ML workers are available. Same logic works for scale up as well as scale down.
Some of the other challenges we encountered were as follows:
Eliminate single points of failure
Run RabbitMQ in High Availability mode with queue replication across three zones in GCP.
Use GCloud Storage as a fallback for Minio. If Minio is unavailable, the application will transparently use GCloud Storage as an image store.
ML workers were split across two availability zones in an odd-even fashion.
For other components (PostgreSQL, Redis, API), we used SaaS offerings by GCP and ran redundant versions of those components.
GPU utilization bug in Nomad (https://github.com/hashicorp/nomad/issues/6708)
We used Raw Exec driver from Nomad and launched multiple ML containers on a single VM using docker-compose.
We also implemented custom health checks and CPU stickiness for individual containers.
Capacity Planning
We figured out the optimal VM setup considering factors like GPU, RAM, and cost per hour.
We studied past request patterns and figured out a simple formula for predicting traffic based on a slope of the request growth line.
Automated Rolling Deployments during peak time
We pre-fetched the ML worker docker images (7GB+) on nodes to have a faster startup time during deployments.
The golden image would be updated on the first node. After it is successfully deployed, it would be updated on all remaining nodes, one at a time. This allowed us to deploy services even during peak load.
Monitoring, Alerting, and auto-healing
We made various SLI reports and latency dashboards available to all stakeholders.
Setup PagerDuty and on-call schedules.
Implemented scripted actions for common operation issues (example: Handling Live VM migration for GPU VMs)
Test the whole setup and fix issues
We Performed extensive, long-running Load tests with production-like traffic patterns to ensure the Autoscaler worked as expected.
Tested redundancies and HA setup by introducing chaos (shutting down of nodes and services like Minio) during load testing.
Tech stack used.
Watch this talk for a detailed understanding of the work, presented at HashiTalks India 2021.













