
A case of Terabyte scale backup and recovery solution
You are a tech lead who's tasked to backup 1.5TB (yes, not a typo, a terabyte) of data DAILY to S3.
You're not really sure about any other background about this requirement, so you start asking some questions:
Where's the data produced from and stored currently?
What kind of data (format) is it really? What's the access pattern for this data?
What data retention do we need?
Why do we need a backup in the first place? Why S3? Is that already decided?
Are we already on AWS?
Can someone share some business context with me?
What are data restoration parameters - e.g., time to restore, where to store the restored data?
How often does the backup need to run? What about the restoration process? How often do we need to run it?
You have many other questions, but you choose to start with these...
You gather answers to these and more:
Context
The company is in the Cybersecurity domain and provides its clients a "Managed Security Services" offering. The data is generated by its multi-tenant SIEM platform deployed on private data centers. The SIEM handles 100s of tenants and produces 1.5 TB of log data daily (tar.gz format). The infra consists of 24 beefy machines in Data Centers (DC). There's a private link between the DC and AWS. Every night, a cron job creates tar.gz files on these 24 machines.
You find out some more details.
The average tar.gz file size per machine is 65GB. (24 machines * ~65GB avg tar.gz file => 1.5TB data daily). Each machine handles a few tenants, and the tar.gz file contains data for these tenants. Currently, tar.gz files are moved to a 200TB archival storage. The current archival process needs fixing. The data needs to be kept for 1 yr for compliance purposes (total data per year could be 700TB, given the growth of the company). There's also a need to re-arrange the data in a specific dir structure before gzipping.
With this, you start designing a high-level solution that will be:
automated
secure
performant
operationally simple to run and
budget-friendly
Exploring the Solution
You also understand more about the SIEM and how it stores this huge data.
You perform a POC to find out whether you can hook into the SIEM to create the required dir structure upfront. This will save a lot of disk IO to read the data, transform it, and write it again to the appropriate format.
With some trial and error, POC is successful.
Since the data is seldom accessed and only used for compliance purposes, you choose the S3 Glacier Deep Archive storage class. This is the cheapest and most reliable way to store the data at this scale.
The challenge is uploading this huge data from the DC to S3 daily.
You test the available bandwidth by uploading large files to S3. This impacts the production network. Luckily, a backup network pipe can be used without affecting the production traffic.
You find out that the 24 VMs are beefy, but they are already serving prod traffic. Running the backup workload causes high CPU utilization and affects prod traffic. So you decide to run the tar.gz operation on a separate central server (in non-prod network)
With these and a few more small POCs in place, you propose this flow for the whole solution.
Solution
create a backup dir structure on each of the 24 VMs via cron job
scp these files to NFS
create tar.gz files on a central server
upload tar.gz to S3
Tech-wise, you choose something simple and boring - bash scripts and cron jobs.
There's some pushback about using bash to do all this work, but you're sure it can work well (and be maintainable).
This is your overall solution:
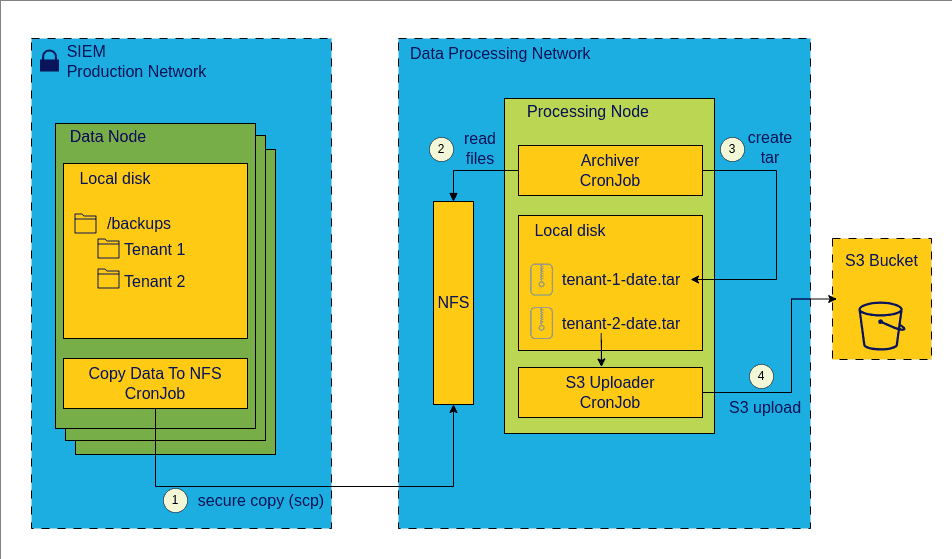
It's just three bash scripts overall, with some error handling and success/failure notifications. You orchestrate the execution of these scripts such that they work like a data pipeline:
scp
tar and
s3 upload
All these operations run in parallel as much as possible. And it works beautifully on production for months without much oversight! You encounter some edge cases during your beta testing, but it's nothing you can't handle at this point.
The entire solution costs less than a few hundred dollars per month to run.
You cross-check your solution goals:
automated (bash and cron ftw!)
secure(runs in separate VPC)
performant (yesterday's data is uploaded within 10 hours, during non-peak time)
operationally simple to run
budget-friendly (less than a few hundred $ monthly)
Lessons
Simple, boring tech works well on prod
When faced with unknowns, form and validate your hypothesis by doing POCs
Understand existing tech and context as much as you can
Build things iteratively instead of in a big-bang way
Be solution-focused, not tech-focused
I write such stories on software engineering. There's no specific frequency as I don't make these up. If you liked this one, you might love - Not all debugging stories have a happy ending





