
Batching your I/O is one of the most reliable pieces of advice in system architecture. So when performance was a problem, enabling batch listeners in Spring Kafka seemed like the obvious move. Spoiler alert: It was not.
This article will go over our journey of enabling batch listeners in Spring Kafka, the neat ways Kafka optimizes for performance out of the box and why you should always RTFM.
Note: The library is officially called Spring for Apache Kafka but that’s a mouthful so I will be referring to it as Spring Kafka throughout this article.
Setting the context
Our use case was as textbook as it gets for adopting Kafka. We have millions of messages coming in per day (~14M) with occasional bursts, but there's no per-message time limit. As long as all messages got processed before the next day, we were good to go.
There could be certain messages that fail transiently and have to be retried. One of the advantages of using Spring Kafka is that it comes with "non-blocking retries" out of the box. The official docs cover how this pattern works in detail but TL;DR - we don't want a failed message to block the rest of the messages in its partition while it gets retried.
What is of interest to us though is that you cannot have non-blocking retries AND batch listeners (Ref. Also, try to think about why this is the case exactly). We were exploring various options to improve the performance of our system and decided to enable batch listeners - at the cost of losing non-blocking retries. We saw a marginal improvement in performance but the system would now be much slower if (or when, if you believe in Murphy's law) the error rate goes up. However, at the time we decided the tradeoff was worth it and moved on.
A lesson on understanding the tools you work with
Months after this was done, I was going over Kafka's design docs. Each decision taken deserves a blog of its own but one thing caught my eye - the section on "End to end batch compression".
The way compression works in Kafka is, at the producer side, a bunch of messages are grouped together, compressed and sent. Batching before compressing the messages leads to better compression ratios as a lot of information tends to be redundant across messages. eg., the keys in JSON messages which can be taken advantage of by compressing a batch together. Each batch of records / messages is called a RecordBatch. (Very original indeed.)
For example, a producer might group a few hundred small JSON messages into a single RecordBatch, compress it once, and send that unit over the wire.
Then, the broker just validates each RecordBatch sent by the producer (eg., ensuring that the number of records match what the header states) before sending it in the same format to the consumers. The RecordBatch is the smallest unit sent over the wire and this is logical as the consumer cannot make use of half a RecordBatch.
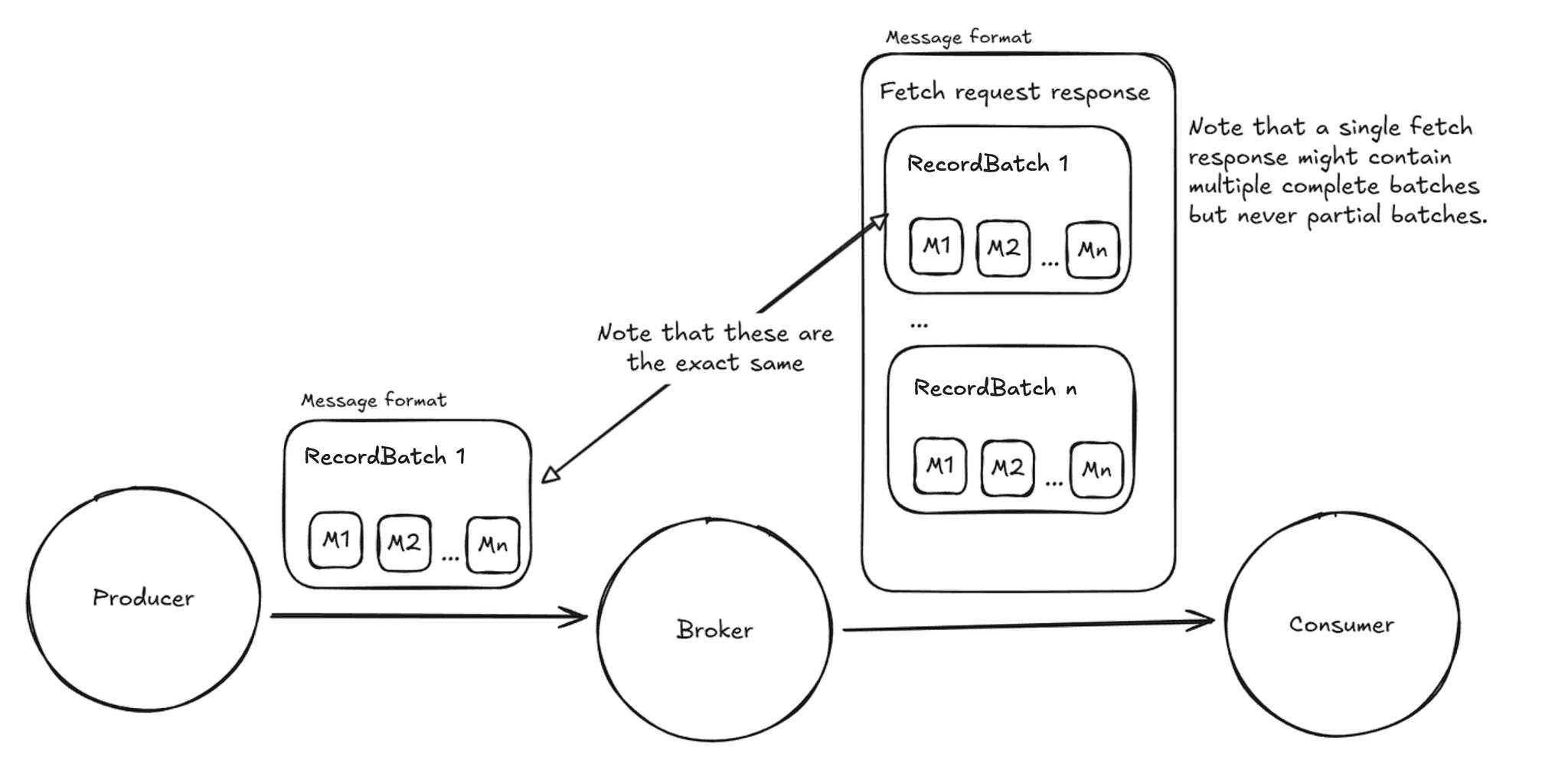
Image: Rough sketch of the message format being sent
Note that setting a different compression type at the topic level would mean that each RecordBatch would be recompressed by the broker using the topic level compression algorithm. However, the messages in each batch would still be the same and the number of messages is decided by the producer and not the broker or consumer. This is the point that is significant for us. Also, having a different compression type at the topic level is usually undesirable as it adds unnecessary load on the broker side with no benefit for most use cases. This doc goes over every combination of the compression configs and explains what it does.
Does max.poll.records affect how Kafka batches messages?
max.poll.records is an application level config and just affects how many records are returned on each call of poll. This does not affect the actual message fetching from the broker to the consumer. The Kafka consumer fetches the batch(es) from the broker and buffers them in memory. Each poll returns records from this buffer up to the limit specified by max.poll.records. The purpose of max.poll.records is to have a reliable upper bound on the processing time and ensure the consumer stays within max.poll.interval.ms and is not accidentally marked dead.
What does fetch.max.bytes actually control?
fetch.max.bytes does affect the actual fetching from broker to the consumer. However, this is not treated as an absolute maximum. If the first batch is larger than this value, it is still returned in order for the consumer to make progress. This is typically used to fetch multiple batches in one go rather than to break batches into fragments. This in combination with fetch.min.bytes can be used to "batch" the batches more or less aggressively from the consumer side.
The key point is that both these configs control how consumers receive and buffer batches, but they do not change how producers group messages into RecordBatches in the first place.
Now with confidence that Kafka maintains a batch of messages intact, from producer, through the broker till the consumer is finally reading the messages, we are left with just one unanswered question:
If Kafka does batching out of the box, what do batch listeners in Spring Kafka even solve?
Batch listeners change how Spring Kafka delivers records to your listener. Instead of processing one record at a time, your listener receives a whole list per invocation. This is only worth doing when your consumer's processing logic actually benefits from working in batches.
One simple and common use case is reading a bunch of messages, transforming them in some manner and then writing the results to a database. Instead of doing a DB write for each record, you can have one batch insert which is much more efficient.
This batch size can be configured by setting the max.poll.records consumer config we discussed.
Since our use case was finding regex matches in individual messages, which neither has side effects that can be batched nor compute that can be done more effectively in a batch, it did not benefit from batch listeners.
Wrapping up
In conclusion, batch listeners were not the correct solution for our use case, especially at the cost of losing non-blocking retries. By going back to record level listeners and re-enabling non-blocking retries, our error handling became simpler and more performant.
If the batch size is misconfigured, it can lead to lower throughput. This however needs to be fixed on the producer side. To configure the producers to batch more aggressively, we increased batch.size, which specifies the batch size in bytes per partition per request. A higher value increases throughput at the cost of a bigger memory footprint and latency, which was an acceptable tradeoff for our use case.
Since Kafka does not wait forever for batches to fill up, batch.size is an upper bound, not a guarantee. We also configured linger.ms, which controls how long the producer waits before sending a batch. The producer will wait for the configured linger duration or until the record batch is of batch.size (whichever happens first) before sending the record batch.
The real lesson was simpler than the fix: before enabling a feature, understand what problem it actually solves. The docs were there all along.
If you enjoy this kind of "we broke it, then fixed it" story, you might also like our posts on real-world Kafka and reliability incidents. Check out Gitops for Kafka in the real world and How Queueing Theory Makes Systems Reliable.
Batching your I/O is one of the most reliable pieces of advice in system architecture. So when performance was a problem, enabling batch listeners in Spring Kafka seemed like the obvious move. Spoiler alert: It was not.
This article will go over our journey of enabling batch listeners in Spring Kafka, the neat ways Kafka optimizes for performance out of the box and why you should always RTFM.
Note: The library is officially called Spring for Apache Kafka but that’s a mouthful so I will be referring to it as Spring Kafka throughout this article.
Setting the context
Our use case was as textbook as it gets for adopting Kafka. We have millions of messages coming in per day (~14M) with occasional bursts, but there's no per-message time limit. As long as all messages got processed before the next day, we were good to go.
There could be certain messages that fail transiently and have to be retried. One of the advantages of using Spring Kafka is that it comes with "non-blocking retries" out of the box. The official docs cover how this pattern works in detail but TL;DR - we don't want a failed message to block the rest of the messages in its partition while it gets retried.
What is of interest to us though is that you cannot have non-blocking retries AND batch listeners (Ref. Also, try to think about why this is the case exactly). We were exploring various options to improve the performance of our system and decided to enable batch listeners - at the cost of losing non-blocking retries. We saw a marginal improvement in performance but the system would now be much slower if (or when, if you believe in Murphy's law) the error rate goes up. However, at the time we decided the tradeoff was worth it and moved on.
A lesson on understanding the tools you work with
Months after this was done, I was going over Kafka's design docs. Each decision taken deserves a blog of its own but one thing caught my eye - the section on "End to end batch compression".
The way compression works in Kafka is, at the producer side, a bunch of messages are grouped together, compressed and sent. Batching before compressing the messages leads to better compression ratios as a lot of information tends to be redundant across messages. eg., the keys in JSON messages which can be taken advantage of by compressing a batch together. Each batch of records / messages is called a RecordBatch. (Very original indeed.)
For example, a producer might group a few hundred small JSON messages into a single RecordBatch, compress it once, and send that unit over the wire.
Then, the broker just validates each RecordBatch sent by the producer (eg., ensuring that the number of records match what the header states) before sending it in the same format to the consumers. The RecordBatch is the smallest unit sent over the wire and this is logical as the consumer cannot make use of half a RecordBatch.
Image: Rough sketch of the message format being sent
Note that setting a different compression type at the topic level would mean that each RecordBatch would be recompressed by the broker using the topic level compression algorithm. However, the messages in each batch would still be the same and the number of messages is decided by the producer and not the broker or consumer. This is the point that is significant for us. Also, having a different compression type at the topic level is usually undesirable as it adds unnecessary load on the broker side with no benefit for most use cases. This doc goes over every combination of the compression configs and explains what it does.
Does max.poll.records affect how Kafka batches messages?
max.poll.records is an application level config and just affects how many records are returned on each call of poll. This does not affect the actual message fetching from the broker to the consumer. The Kafka consumer fetches the batch(es) from the broker and buffers them in memory. Each poll returns records from this buffer up to the limit specified by max.poll.records. The purpose of max.poll.records is to have a reliable upper bound on the processing time and ensure the consumer stays within max.poll.interval.ms and is not accidentally marked dead.
What does fetch.max.bytes actually control?
fetch.max.bytes does affect the actual fetching from broker to the consumer. However, this is not treated as an absolute maximum. If the first batch is larger than this value, it is still returned in order for the consumer to make progress. This is typically used to fetch multiple batches in one go rather than to break batches into fragments. This in combination with fetch.min.bytes can be used to "batch" the batches more or less aggressively from the consumer side.
The key point is that both these configs control how consumers receive and buffer batches, but they do not change how producers group messages into RecordBatches in the first place.
Now with confidence that Kafka maintains a batch of messages intact, from producer, through the broker till the consumer is finally reading the messages, we are left with just one unanswered question:
If Kafka does batching out of the box, what do batch listeners in Spring Kafka even solve?
Batch listeners change how Spring Kafka delivers records to your listener. Instead of processing one record at a time, your listener receives a whole list per invocation. This is only worth doing when your consumer's processing logic actually benefits from working in batches.
One simple and common use case is reading a bunch of messages, transforming them in some manner and then writing the results to a database. Instead of doing a DB write for each record, you can have one batch insert which is much more efficient.
This batch size can be configured by setting the max.poll.records consumer config we discussed.
Since our use case was finding regex matches in individual messages, which neither has side effects that can be batched nor compute that can be done more effectively in a batch, it did not benefit from batch listeners.
Wrapping up
In conclusion, batch listeners were not the correct solution for our use case, especially at the cost of losing non-blocking retries. By going back to record level listeners and re-enabling non-blocking retries, our error handling became simpler and more performant.
If the batch size is misconfigured, it can lead to lower throughput. This however needs to be fixed on the producer side. To configure the producers to batch more aggressively, we increased batch.size, which specifies the batch size in bytes per partition per request. A higher value increases throughput at the cost of a bigger memory footprint and latency, which was an acceptable tradeoff for our use case.
Since Kafka does not wait forever for batches to fill up, batch.size is an upper bound, not a guarantee. We also configured linger.ms, which controls how long the producer waits before sending a batch. The producer will wait for the configured linger duration or until the record batch is of batch.size (whichever happens first) before sending the record batch.
The real lesson was simpler than the fix: before enabling a feature, understand what problem it actually solves. The docs were there all along.
If you enjoy this kind of "we broke it, then fixed it" story, you might also like our posts on real-world Kafka and reliability incidents. Check out Gitops for Kafka in the real world and How Queueing Theory Makes Systems Reliable.
In this post
In this post
Section
Share
Share
In this post
section
Share
Keywords
Kafka batching, End to end batch compression, spring kafka batch listeners, kafka non blocking retries, spring for apache kafka batching, Message Queues, max.poll.records vs fetch.max.bytes












