Context.
We work with a large-scale enterprise in digital communications governance domain as a SaaS provider (~$300M ARR). They use Apache Kafka to power their event-driven architecture. One of their products was being rolled out to many new tenants (increasing the traffic by 2x). During this roll out phase, their Kafka-based async data pipeline experienced significant performance degradation. This caused cascading ripple effects throughout the other system, making the product unusable. We investigated and fixed this problem and eventually enabled the product to support 4 times the anticipated scale.
Problem Statement.
Fix performance bottleneck: Figure out the performance bottleneck in the event-driven architecture and fix it.
Fix performance bottleneck: Figure out the performance bottleneck in the event-driven architecture and fix it.
Fix performance bottleneck: Figure out the performance bottleneck in the event-driven architecture and fix it.
High infrastructure costs: Ensure infrastructure costs don’t increase excessively in proportion to the incoming load on the system.
High infrastructure costs: Ensure infrastructure costs don’t increase excessively in proportion to the incoming load on the system.
High infrastructure costs: Ensure infrastructure costs don’t increase excessively in proportion to the incoming load on the system.
High latency: Improve the message producer/consumer latency (which shot up to 30 milliseconds from less than 5 milliseconds earlier, causing 6x worse performance and cascading delays in event processing pipeline).
High latency: Improve the message producer/consumer latency (which shot up to 30 milliseconds from less than 5 milliseconds earlier, causing 6x worse performance and cascading delays in event processing pipeline).
High latency: Improve the message producer/consumer latency (which shot up to 30 milliseconds from less than 5 milliseconds earlier, causing 6x worse performance and cascading delays in event processing pipeline).
Low throughput: Improve system throughput. The existing system processed only 5,000 messages per second, whereas the target was to support at least 3x of that scale.
Low throughput: Improve system throughput. The existing system processed only 5,000 messages per second, whereas the target was to support at least 3x of that scale.
Low throughput: Improve system throughput. The existing system processed only 5,000 messages per second, whereas the target was to support at least 3x of that scale.
Outcome/Impact.
90%
90%
90%
Latency Improvement
Latency Improvement
Latency Improvement
4x
4x
4x
Throughput improvements
Throughput improvements
Throughput improvements
40%
40%
40%
Cost reduction
Cost reduction
Cost reduction
Improve performance: Allow product team to roll out the product across 3x more tenants with improved performance.
Improve performance: Allow product team to roll out the product across 3x more tenants with improved performance.
Improve performance: Allow product team to roll out the product across 3x more tenants with improved performance.
Improve performance: Allow product team to roll out the product across 3x more tenants with improved performance.
Cost savings: Optimise infrastructure spend by 40% (reduce the hardware footprint required to support the growing scale)
Cost savings: Optimise infrastructure spend by 40% (reduce the hardware footprint required to support the growing scale)
Cost savings: Optimise infrastructure spend by 40% (reduce the hardware footprint required to support the growing scale)
Cost savings: Optimise infrastructure spend by 40% (reduce the hardware footprint required to support the growing scale)
Latency improvements: Message producer/consumer latency reduced from 30 milliseconds to 2 milliseconds (90% improvement).
Latency improvements: Message producer/consumer latency reduced from 30 milliseconds to 2 milliseconds (90% improvement).
Latency improvements: Message producer/consumer latency reduced from 30 milliseconds to 2 milliseconds (90% improvement).
Latency improvements: Message producer/consumer latency reduced from 30 milliseconds to 2 milliseconds (90% improvement).
Throughput enhancements: Kafka message throughput increased from 5,000 messages per second to 20,000 messages per second (4x improvement).
Throughput enhancements: Kafka message throughput increased from 5,000 messages per second to 20,000 messages per second (4x improvement).
Throughput enhancements: Kafka message throughput increased from 5,000 messages per second to 20,000 messages per second (4x improvement).
Throughput enhancements: Kafka message throughput increased from 5,000 messages per second to 20,000 messages per second (4x improvement).
Solution.
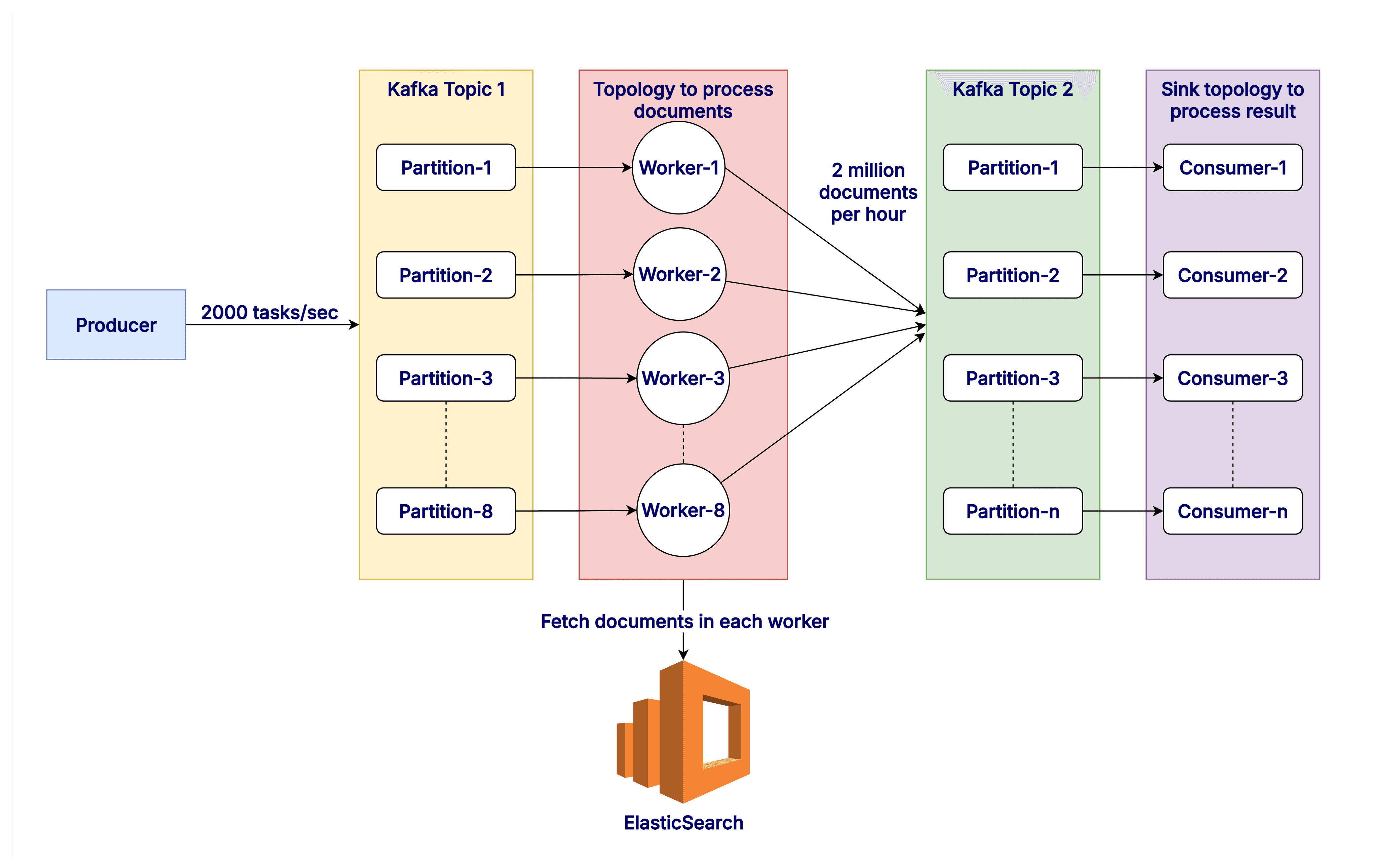
Asynchronous data processing pipeline architecture
The backend architecture for the product consists of asynchronous data processing pipelines as shown in the diagram above. Kafka is used as a message broker and various workers act as producer and consumers across different topics and partitions.
The data pipeline consists of a Kafka producer that inserts 2000 messages per second into a Kafka topic. There are eight partitions in that topic and correspondingly, eight consumers (we call them workers in the diagram). Each of the workers perform the required business logic and finally generate 2 Million messages to be sent to new topic for further processing.
As the system experienced more scale (due to increase in tenants), the message volume increased in Kafka. This resulted in an increased latency in message processing going from 5 ms to 30 ms. At this point, we paused the further roll-out and started investigating this performance degradation.
After a lot of debugging and simulating the load in staging environment, we found the culprit.
The existing Kafka configuration resulted in excessive resource usage, increased latency, and inefficient data transfer. This inefficiency led to higher infrastructure costs and performance bottlenecks, affecting system scalability and reliability.
To fix this, we simulated the load on staging environment and narrowed down the problem to unoptimised Kafka configuration. In particular, the following three config options:
Linger.ms: (the maximum time to buffer messages before sending a batch to improve the throughput)
Batch.size: (the maximum size in bytes of a batch for each partition before it's sent)
Compression.type: (the compression algorithm e.g., gzip, snappy, used to reduce message size before sending)
We wrote performance test suite to test various options for these config parameters to find out the optimal config value for our use case. We cover the details about this benchmarking process in a recent talk.
After analyzing the results, we identified the best configuration for the system as:
Batch Size: 65 KB
Linger Time: 500 milliseconds
Compression: Snappy
With these settings, Kafka efficiently grouped and compressed messages, reducing network calls and improving throughput while maintaining a reasonable CPU load. We deployed the new configuration in a staging environment, tested it under production-like traffic, and then rolled out in production.
By leveraging automated benchmarking, methodical testing, and data-driven optimization, we were able to significantly enhance Kafka’s performance, reducing costs while maintaining scalability and reliability.

Asynchronous data processing pipeline architecture
The backend architecture for the product consists of asynchronous data processing pipelines as shown in the diagram above. Kafka is used as a message broker and various workers act as producer and consumers across different topics and partitions.
The data pipeline consists of a Kafka producer that inserts 2000 messages per second into a Kafka topic. There are eight partitions in that topic and correspondingly, eight consumers (we call them workers in the diagram). Each of the workers perform the required business logic and finally generate 2 Million messages to be sent to new topic for further processing.
As the system experienced more scale (due to increase in tenants), the message volume increased in Kafka. This resulted in an increased latency in message processing going from 5 ms to 30 ms. At this point, we paused the further roll-out and started investigating this performance degradation.
After a lot of debugging and simulating the load in staging environment, we found the culprit.
The existing Kafka configuration resulted in excessive resource usage, increased latency, and inefficient data transfer. This inefficiency led to higher infrastructure costs and performance bottlenecks, affecting system scalability and reliability.
To fix this, we simulated the load on staging environment and narrowed down the problem to unoptimised Kafka configuration. In particular, the following three config options:
Linger.ms: (the maximum time to buffer messages before sending a batch to improve the throughput)
Batch.size: (the maximum size in bytes of a batch for each partition before it's sent)
Compression.type: (the compression algorithm e.g., gzip, snappy, used to reduce message size before sending)
We wrote performance test suite to test various options for these config parameters to find out the optimal config value for our use case. We cover the details about this benchmarking process in a recent talk.
After analyzing the results, we identified the best configuration for the system as:
Batch Size: 65 KB
Linger Time: 500 milliseconds
Compression: Snappy
With these settings, Kafka efficiently grouped and compressed messages, reducing network calls and improving throughput while maintaining a reasonable CPU load. We deployed the new configuration in a staging environment, tested it under production-like traffic, and then rolled out in production.
By leveraging automated benchmarking, methodical testing, and data-driven optimization, we were able to significantly enhance Kafka’s performance, reducing costs while maintaining scalability and reliability.













