Context.
The customer is a B2B fintech company in the cross border payments space. Their daily transaction volume is in the range of $50M to $70M. For this, they query multiple terabytes of data across their analytics infrastructure.
Their analytics platform was built entirely on AWS managed services: AWS DMS for CDC replication from PostgreSQL, AWS Glue jobs for ETL, AWS Glue tables using S3 for storage as their database, and Amazon Athena for querying. The existing analytics platform worked fine initially, but as data volumes grew, monthly costs crossed from $13,000 and were heading toward $35,000 with projected 3x growth.
The analytics solution did not justify the cost to the business. One2N helped to migrate them to a self-hosted open-source stack and cut their costs by 70% while maintaining production-grade reliability.
Problem Statement.
Escalating infrastructure costs: Analytics spend exceeding $13,000/month with no optimization levers available in fully managed services.
Escalating infrastructure costs: Analytics spend exceeding $13,000/month with no optimization levers available in fully managed services.
Escalating infrastructure costs: Analytics spend exceeding $13,000/month with no optimization levers available in fully managed services.
Scalability concerns: Projected 3x volume growth would push monthly costs beyond $35,000, unsustainable for unit economics.
Scalability concerns: Projected 3x volume growth would push monthly costs beyond $35,000, unsustainable for unit economics.
Scalability concerns: Projected 3x volume growth would push monthly costs beyond $35,000, unsustainable for unit economics.
No operational control: Can't tune compression, storage optimization, or resource allocation with managed services.
No operational control: Can't tune compression, storage optimization, or resource allocation with managed services.
No operational control: Can't tune compression, storage optimization, or resource allocation with managed services.
Vendor lock-in: Entire pipeline built on AWS-specific services, limiting negotiating power and strategic flexibility.
Vendor lock-in: Entire pipeline built on AWS-specific services, limiting negotiating power and strategic flexibility.
Outcome/Impact.
70%
70%
70%
Cost reduction
Cost reduction
Cost reduction
$108K
$108K
$108K
Annual Savings
Annual Savings
Annual Savings
81%
81%
81%
Compression in DB size
Compression in DB size
Compression in DB size
Cost savings: Monthly spend dropped from $13,000 to $4,000. That's $9,000/month or roughly $108K year.
Cost savings: Monthly spend dropped from $13,000 to $4,000. That's $9,000/month or roughly $108K year.
Cost savings: Monthly spend dropped from $13,000 to $4,000. That's $9,000/month or roughly $108K year.
Cost savings: Monthly spend dropped from $13,000 to $4,000. That's $9,000/month or roughly $108K year.
Production-ready reliability: 1-shard, 2-replica ClickHouse cluster with 99%+ availability across availability zones.
Production-ready reliability: 1-shard, 2-replica ClickHouse cluster with 99%+ availability across availability zones.
Production-ready reliability: 1-shard, 2-replica ClickHouse cluster with 99%+ availability across availability zones.
Production-ready reliability: 1-shard, 2-replica ClickHouse cluster with 99%+ availability across availability zones.
Query performance maintained: P95 latency of 4.2 seconds on par with what they had on Athena.
Query performance maintained: P95 latency of 4.2 seconds on par with what they had on Athena.
Query performance maintained: P95 latency of 4.2 seconds on par with what they had on Athena.
Query performance maintained: P95 latency of 4.2 seconds on par with what they had on Athena.
Full operational control: Team now owns compression algorithms, indexing strategies, and resource allocation.
Full operational control: Team now owns compression algorithms, indexing strategies, and resource allocation.
Full operational control: Team now owns compression algorithms, indexing strategies, and resource allocation.
Full operational control: Team now owns compression algorithms, indexing strategies, and resource allocation.
No more lock-in: Entire stack is open-source (ClickHouse, PeerDB, Prefect, dbt). It gives flexibility to the customer to move anywhere.
No more lock-in: Entire stack is open-source (ClickHouse, PeerDB, Prefect, dbt). It gives flexibility to the customer to move anywhere.
No more lock-in: Entire stack is open-source (ClickHouse, PeerDB, Prefect, dbt). It gives flexibility to the customer to move anywhere.
No more lock-in: Entire stack is open-source (ClickHouse, PeerDB, Prefect, dbt). It gives flexibility to the customer to move anywhere.
Solution.
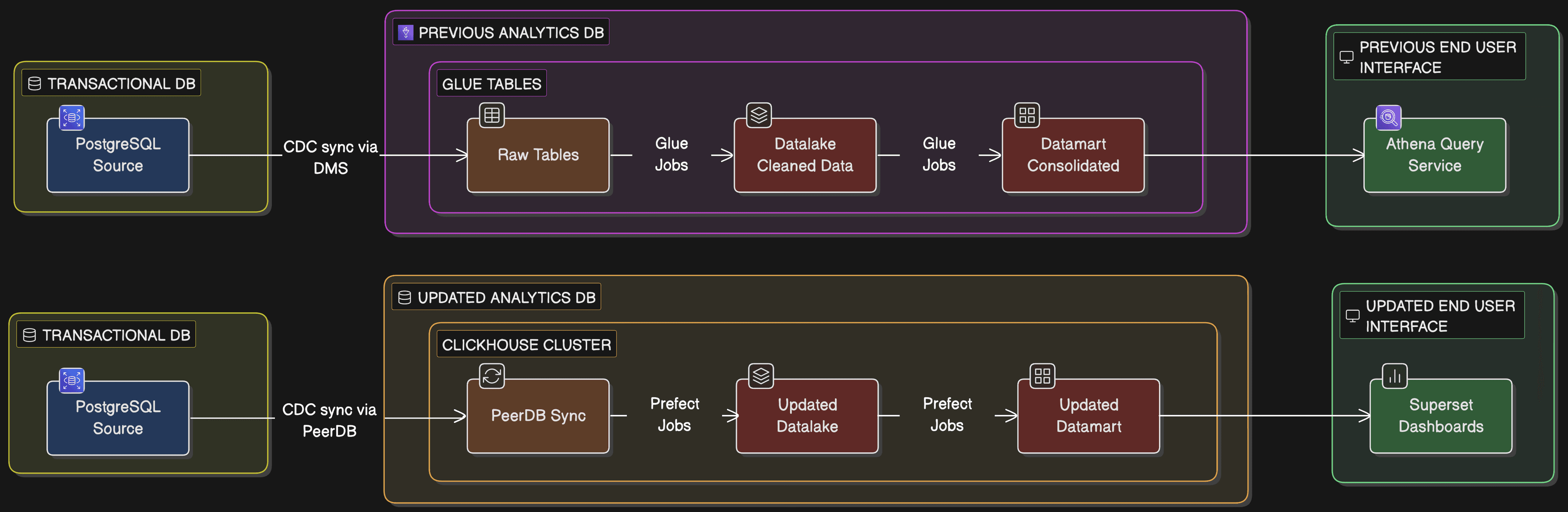
Previous Setup vs Updated Setup
The original setup relied on a fully managed AWS stack: DMS for CDC from PostgreSQL, S3 for storage, Glue for processing, and Athena for queries. It was reliable, but at terabyte scale, it was costing a fortune with no way to optimize. We broke the migration into four logical phases to ensure a smooth transition with zero downtime.
Phase 1: Building the ClickHouse Foundation (~$6,400 to ~$3,600/month)
The heart of the new stack is a self-hosted ClickHouse cluster. We opted for a pragmatic 1-shard, 2-replica (1S2R) architecture.
Why only 1 shard? Their current data fits comfortably in a single node with plenty of room to grow. Sharding adds significant operational overhead (distributed query complexity, rebalancing), so we decided to keep it simple and only scale horizontally when the data actually demands it.
The Infrastructure: We used Graviton-based r6g.4xlarge instances. Graviton gives us a ~20% price-performance edge over x86 for ClickHouse workloads. To ensure fault tolerance, we deployed a 2-node ClickHouse Keeper cluster spread across multiple availability zones.
Observability: Moving off managed services means you own the monitoring. We wired in OpenTelemetry and Last9 from day one to track cluster health, replication lag, and query performance.
Phase 2: Transitioning to PeerDB for CDC (~$3,500 to ~$60/month)
With the cluster ready, we needed a more cost-effective way to keep data flowing. AWS DMS was costing $3,500/month just for replication. We replaced it with PeerDB, an open-source tool built specifically for PostgreSQL-to-ClickHouse pipelines. It maintained the same 30-second sync intervals but slashed the cost by 98%. It’s a classic case of a specialized tool outperforming a general-purpose managed service.
Phase 3: Streamlining ETL with Prefect and dbt (~$3,000 to ~$60/month)
Next, we replaced the "black box" of Glue Spark jobs. Prefect handles the orchestration, managing the dependencies between the datalake and datamart layers and executing jobs with the transformation logic. dbt allows the team to use version-controlled, testable SQL instead of complex Spark code to maintain our schemas.
Phase 4: Consuming Analytics with Apache Superset (~$20 to ~$60/month)
Finally, we replaced the Athena query layer with Apache Superset. While Athena’s pay-per-query model seems cheap initially, it becomes a deterrent for exploration at scale. By running Superset on a dedicated instance, we gave the analytics team unlimited query access with no per-scan charges. They now have full-featured dashboards, alerts, and regulatory reporting on a predictable, fixed-cost infrastructure.
Why go all-in on Open Source?
By choosing ClickHouse, PeerDB, Prefect, and dbt, we eliminated licensing fees and vendor lock-in. The client now has full operational transparency and the flexibility to move their stack anywhere be it on-prem or to another cloud provider, without rebuilding their entire data culture.
Tech stack used.
Component | Technology |
|---|---|
Analytical DB | |
CDC Replication | |
Orchestration | |
Schema Migrations | |
Observability | |
Compute | |
Storage | |
Dashboards and Alerts |

Previous Setup vs Updated Setup
The original setup relied on a fully managed AWS stack: DMS for CDC from PostgreSQL, S3 for storage, Glue for processing, and Athena for queries. It was reliable, but at terabyte scale, it was costing a fortune with no way to optimize. We broke the migration into four logical phases to ensure a smooth transition with zero downtime.
Phase 1: Building the ClickHouse Foundation (~$6,400 to ~$3,600/month)
The heart of the new stack is a self-hosted ClickHouse cluster. We opted for a pragmatic 1-shard, 2-replica (1S2R) architecture.
Why only 1 shard? Their current data fits comfortably in a single node with plenty of room to grow. Sharding adds significant operational overhead (distributed query complexity, rebalancing), so we decided to keep it simple and only scale horizontally when the data actually demands it.
The Infrastructure: We used Graviton-based r6g.4xlarge instances. Graviton gives us a ~20% price-performance edge over x86 for ClickHouse workloads. To ensure fault tolerance, we deployed a 2-node ClickHouse Keeper cluster spread across multiple availability zones.
Observability: Moving off managed services means you own the monitoring. We wired in OpenTelemetry and Last9 from day one to track cluster health, replication lag, and query performance.
Phase 2: Transitioning to PeerDB for CDC (~$3,500 to ~$60/month)
With the cluster ready, we needed a more cost-effective way to keep data flowing. AWS DMS was costing $3,500/month just for replication. We replaced it with PeerDB, an open-source tool built specifically for PostgreSQL-to-ClickHouse pipelines. It maintained the same 30-second sync intervals but slashed the cost by 98%. It’s a classic case of a specialized tool outperforming a general-purpose managed service.
Phase 3: Streamlining ETL with Prefect and dbt (~$3,000 to ~$60/month)
Next, we replaced the "black box" of Glue Spark jobs. Prefect handles the orchestration, managing the dependencies between the datalake and datamart layers and executing jobs with the transformation logic. dbt allows the team to use version-controlled, testable SQL instead of complex Spark code to maintain our schemas.
Phase 4: Consuming Analytics with Apache Superset (~$20 to ~$60/month)
Finally, we replaced the Athena query layer with Apache Superset. While Athena’s pay-per-query model seems cheap initially, it becomes a deterrent for exploration at scale. By running Superset on a dedicated instance, we gave the analytics team unlimited query access with no per-scan charges. They now have full-featured dashboards, alerts, and regulatory reporting on a predictable, fixed-cost infrastructure.
Why go all-in on Open Source?
By choosing ClickHouse, PeerDB, Prefect, and dbt, we eliminated licensing fees and vendor lock-in. The client now has full operational transparency and the flexibility to move their stack anywhere be it on-prem or to another cloud provider, without rebuilding their entire data culture.
Tech stack used.
Component | Technology |
|---|---|
Analytical DB | |
CDC Replication | |
Orchestration | |
Schema Migrations | |
Observability | |
Compute | |
Storage | |
Dashboards and Alerts |













